
shine's dev log
[논문] Detecting fake accounts in online social networks at the time of registrations 본문
[논문] Detecting fake accounts in online social networks at the time of registrations
dong1 2022. 3. 5. 01:51논문 제목 : Detecting fake accounts in online social networks at the time of registrations
0. abstract
online social networks에서 수많은 fake accounts를 생성해 악용하는 sybil attack이 자주 발생하고 있다.
기존의 sybil detection 방식은 너무 rich한 content, behavior, social graphs 를 이용하여 탐지 과정에서 큰 delay를 발생시킨다는 문제가 존재한다.
이에 본 논문에서는 Ianus 라 불리는 sybil detection 방식을 제안한다.
Ianus는 계정이 등록되는 단계에서 탐지하기 때문에 보다 sybil attack에 대한 보다 빠른 대처가 가능하다.
우선 중국에서 최대 규모의 social network 서비스인 WeChat에서의 registration datase을 사용하였다. 해당 데이터셋에서는 Sybils 에 대한 label이 기록되어 있다. 본 연구진은 Sybils와 benign users의 registration pattern을 측정하는 방안을 고안하였다.
앞서 측정한 결과를 바탕으로 graph inference problem 방식으로 sybil detection 모델을 고안하였다. graph 모델을 통해 heterogeneous 한 feature들을 integrate 할 수 있으며, 각 계정마다 feature를 이용해 graph를 생성하여 sybils 들끼리 얼마나 밀집되어있고, benign user들은 얼마나 sparse 하게 위치해있는지를 파악함으로써 Sybils를 탐지하게 된다.
Ianus 는 WeChat registration 데이터셋을 통해 evaluation을 진행하게 되며, WeChat은 Ianus를 통해 새로 등록하는 account에서 Sybils를 탐지하게 된다. 그 결과 Ianus가 400K개 이상의 registration account를 검사하고, 약 96% 이상의 정확도를 보임을 알 수 있었다.
1. Introduction
트위터 등과 같은 social network 서비스에서 fake account들로 인한 다양한 문제들이 발생하고 있다.
기존의 sybil detection 방식들은 content(URL in tweets), behavior(clickstream), social graphs(friendship graphs) 등의 방식을 통해 Sybils를 탐지하고 있다.
하지만 해당 방식들은 delay가 너무 심해, 탐지하기 전에 이미 다양한 malicious task들을 저질러버리는 경우가 많다. 따라서 본 연구에서는 registration 단에서 sybil attack을 탐지하는 방안을 제안한다.
기존에도 CAAPTCHA 등을 통해 registration 단에서 fake account를 탐지하는 방안들이 있지만, 쉽게 우회된다는 문제가 항상 존재해왔다. 이를 해결하기 위해 첫번째로, 본 연구에서는 WeChat registration 데이터셋을 사용한다.
해당 데이터셋에는 770K 개의 benign users, 647K 개의 sybils account 데이터로 구성되어있다.
각 account 데이터에는 IP address, phone number, device ID, nickname 등의 정보가 담겨있다.
이를 통해 sybils 들이 synchronized 된 패턴, 가령 같은 IP prefix 사용과 같은 것을 이용한다는 것을 알 수 있다. 하지만 이 정보만 가지고는 완벽하게 탐지할 수 없기 때문에 보다 심도있는 패턴 분석이 필요하다.
두번째로, 확보한 패턴 분석 결과를 이용해 sybils를 탐지하는 시스템인 Ianus를 고안하였다. 가장 중요한 부분은 registration data에 있는 synchronized하고 abnormal한 패턴들이 heterogeneous한데, 이를 integrate 하는 것이다.
Ianus에서는 integration을 위해 graph inference techniques를 사용하였다. synchronized 하고 abnormal한 registration 패턴들을 이용해 weighted graph를 만들고, graph를 분석해 sybils를 분석하는 것이다.
graph에서 각 노드는 account 이다. 따라서 sybil node끼리는 densly하게 연결되어있을 것이고, benign node끼리는 sparse 하게 연결되어 있을 것이다.
이러한 목적을 달성하기 위해 Ianus는 3가지 단계를 거친다.
1) feature extraction 2) graph building 3) Sybil detection
feature extraction 단계에서는 우선 2개의 account를 짝지은 후, 해당 쌍의 account의 비슷한 정도를 나타내는 synchronization based feature와 정상적이지 않은 정도를 나타내는 anomaly based features를 추출한다.
예를들어 한쌍의 account가 같은 device를 쓰는 경우 synchronization feature에서 탐지될 것이며, 같은 device를 서로 다른 account 를 만드는데 쓰는게 정상적이지 않으므로 anomaly based feature에서 확인될 것이다.
graph building 단계에서는 앞서 생성한 synchronization based feature와 anomaly based feature 를 기반으로 account들 간의 weighted grpah를 생성할 것이다. 특히 각 account 쌍에게 feature 값을 기반으로 'sync-anomaly score'를 매길 것이다.
따라서 만약 한쌍의 account가 서로 synchronized 하거나 anomaly한 패턴을 가질 경우, sync-anomaly score가 높게 나타날 것이다.
즉, sync-anomaly score는 binary feature(True or False)들의 합으로 산출이 된다. 그러나 단순하게 더하는 것은 각 feature들의 weight 가 고려되지 않는 방식이므로, ML 의 logistic regression을 통해 sync-anomaly score에 적용되는 weight를 학습할 것이다. 이후에 graph를 그릴 때 각 노드를 연결하는 edge에 이 sync-anomaly score가 들어갈 것이다.
Sybil detection 단계에서는 실제 Sybils 를 탐지하는 단계로, community detection 알고리즘이 사용된다. 각 노드들에는 weighted node degree가 존재하는데, 이는 해당 노드와 연결된 edge의 weight에 비례해 결정된다. 따라서 특정 노드의 degree가 높다면, 해당 노드가 sybil일 확률이 높은 것이다.
이러한 node degree based community detection 알고리즘을 사용하여 Sybil detection을 수행하게 된다.
세번째로, 제안한 Lanus 모델을 평가하기 위해 WeChat 데이터를 사용할 것이다. 평가한 결과 Lanus는 80.2%의 recall과 92.4%의 precision이라는 높은 성능으로 잘 동작하는 것을 확인할 수 있었다.
특히 각 단계별로 다양한 design을 적용함으로써 성능을 확인하였다. 예를 들어 feature extraction 단계에서는 synchronization based feature와 anomaly based feature가 상호 보완적으로 동작한 다는 것을 확인 했으며, 이 두 feature를 잘 결합할 경우 높은 성능을 나타내는 것을 확인할 수 있었다.
또한 graph building 단계에서는 logistic regression을 통해 각 feature별로 서로 다른 weight를 적용하였을 때 높은 성능을 내는 것을 확인할 수 있었다.
마지막으로 Sybil detecion 단계에서는 community detection 방식으로 Louvain method를 사용해보았다.
하지만, 실제 실험 결과 Louvain method에 비해 본 논문에서 제안하는 node degree based community detecion 방식을 사용하였을 때, 탐지에 걸리는 시간이 훨씬 줄어드는 것을 확인할 수 있었다.
그 결과, WeChat에서는 Ianus가 하루에 400K 정도의 새로운 registred account를 확인할 수 있고 정확도 또한 96% 정도의 성능을 낸다고 평가하였다.
요약해보면, 본 논문에서는 크게 3가지의 contributions를 가진다.
1) large-scale의 데이터 분석을 통해 Sybils 와 benign account의 특징을 잡아냈다. Sybils는 synchronized와 abnormal registration 패턴을 동시에 가짐을 확인할 수 있었다.
2) Ianus는 각 노드들 간의 synchronized & abnormal pattern과 graph 구조 분석을 통해 Sybils를 탐지할 수 있음을 보였다.
3) 제안한 Ianus를 WeChat의 registration 데이터를 통해 평가하였고, 실제 WeChat에서 Ianus를 사용하는 등 실제 환경에서도 Ianus가 잘 동작함을 보였다.
2. Related work
기존의 sybil detection 기법들은 대부분 사용자들의 content, behavior나 sybils로부터 생성된 social graph 를 활용하는 경우가 많다.
특히 social graph를 이용해 grpah-based ML 기술을사용한 연구들의 경우, 사용자들의 rich feature를 기반으로 동작하기 때문에 delay가 발생한다는 문제가 있다.
하지만 본 논문에서 제안하는 Ianus의 경우, registration 데이터만을 사용하므로 delay가 매우 적다.
3. Measuring registration patterns
3.1. WeChat and Dataset
WeChat 은 현재 중국에서 가장 인기있는 OSN(Online Social Network)이다.
본 연구팀은 WeChat에서 benign & sybil user의 accounts를 획득하였다. WeChat 보안팀에 의하면 해당 데이터셋의 라벨링은 약 95%의 정확도를 가지고 있다. 100%가 아니라 살짝 문제가 될 순 있지만, 본 연구팀에서는 이정도는 크게 개의치 않을 것이라 판단하였다.
데이터셋의 데이터들은 아래 [그림 1]과 같은 Attributes를 가진다.

3.2. Synchronization
Sybils들은 registration 과정에서 공통적인 패턴을 가진다.
본 논문에서는 이 공통적인 패턴을 'Synchronizaed register patterns'라 부를 것이다. 지금부터 각 attributes 별로 이 synchronized 패턴의 measurement 결과를 살펴보자.
1) IP
WeChat은 IPv4 주소를 지원한다. 물론 최근 CIDR 과 같은 주소 체계는 prefix가 같다고 무조건 같은 위치에서 접속한 것이라는 보장은 없지만, 실험결과 그냥 그렇다고 생각할 때 의미 있는 결과가 나왔기에, 같은 prefix가 유의미 하다고 가정하였다.
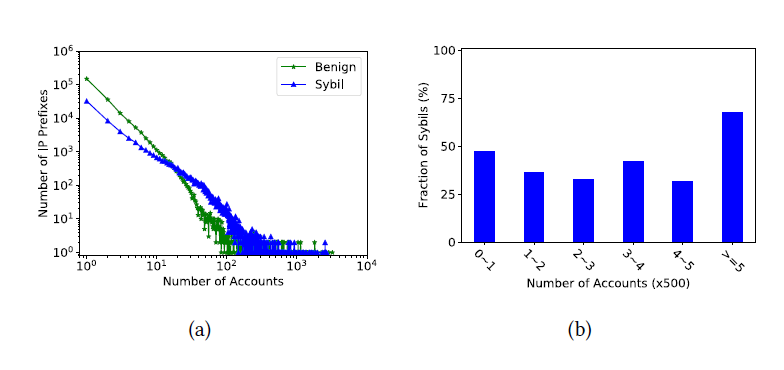
그림 2의 (a) 그림과 같이 그래프로 Account의 수와 Prefixes 의 수를 매핑해본 결과, power law를 따르는 분포가 나왔으며, 80%의 account들이 benign 과 sybil account들의 경우 각각 34.5%, 15.5% 의 prefix 에서 registration 된 것을 확인할 수 있었다. 즉, sybil account는 benign account에 비해 특정 prefix 에 몰려있는 것이다.
또한 그림 2의 (b) 그림은 특정 IP prefix에 account가 가입된 경우, Sybil account의 비율을 나타낸 것이다. 그림에서 볼 수 있듯이, 비교적 적은 수의 accounts들이 동일한 IP prefix를 통해 가입된 경우, sybil 이라 할 순 없지만, 비교적 많은 수의 accounts 들이 동일한 IP prefix를 통해 가입된 경우, 해당 accounts들이 sybils 일 확률이 높았다.
2) Phone number
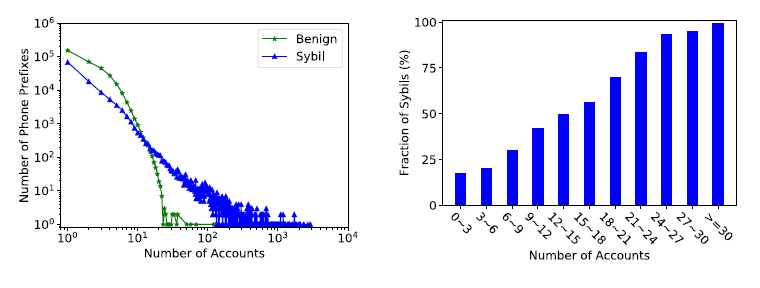
전화 번호의 경우, 마지막 4자리를 제외하면 지역번호와 통신사 번호로 할당된다. 따라서 본 논문에서는 마지막 4자리는 삭제된 채로 실험을 진행하였다.
measurement 결과, IP 와 거의 비슷한 경향을 나타냈는데, 그 결과는 [그림 3]과 같다. Sybils account일 경우 특정 전화 번호에 몰리는 경향이 있으며, 비교적 많은 수의 accounts 들이 동일한 전화 번호를 사용할 경우, sybil account일 확률이 높았다.
3) Device
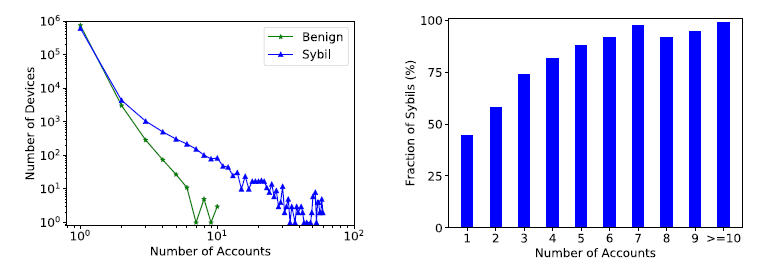
[그림 4]에서 확인할 수 있듯이, Device도 IP나 Phone number와 같은 경향을 가지고 있다.
4) nickname
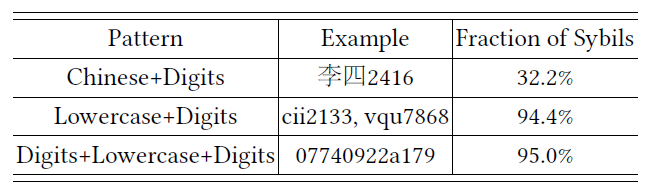
[그림 5]에서 확인할 수 있듯이, Sybil account의 경우, nickname으로 소문자+숫자 조합이나 숫자+소문자+숫자 조합을 많이 사용한 것을 확인할 수 있다.
위와 같은 attributes의 결과를 통해 단순하게 Sybil detector를 만들 수도 있다. 예를 들어 하루에 특정 개수 이상의 동일한 IP prefix를 사용할 경우, Sybil account라고 판단하면 거의 100%의 precision을 가질 수 있다.
하지만, 본 데이터셋에 이렇게 단순한 detector를 구현할 경우, 단지 59%의 recall을 나타낸다. 즉, Sybil account가 있더라도 절반은 탐지를 못하고 놓친다는 말이다.
따라서 본 연구에서는 이번 절에서 살펴본 synchronization patterns of attributes 뿐 아니라, 다음 절에서 살펴볼 anomaly patternes 또한 고려할 것이다.
3.3. Anomaly
앞서 살펴본 synchronization 패턴만 가지고는 sybils를 가려내는데 한계가 있다. 예를 들어 특정 IP prefix에서 여러개의 accounts들이 가입을 했다고 했을 때 이를 sybils나 bening account 라고 단정하기는 어렵다.
하지만 특정 시간대 (예를 들어 새벽)에 동시에 여러개의 accounts들이 가입을 한다면 이는 abnormal 한 패턴이고, 이럴 경우 sybils 일 확률이 더 올라간다. 다양한 anomaly 패턴들을 살펴보자.
1) Registration time
아래 [그림 6]은 특정 IP prefix를 사용해 가입한 accounts에 대하여 가입 시간을 그래프로 나타낸 것이다. 대체적으로 benign accounts들은 낮이나 밤에 가입을 자주 하며, sybil accounts들은 새벽에 동시다발적으로 가입을 하는 경향을 띄는 것을 확인할 수 있다.
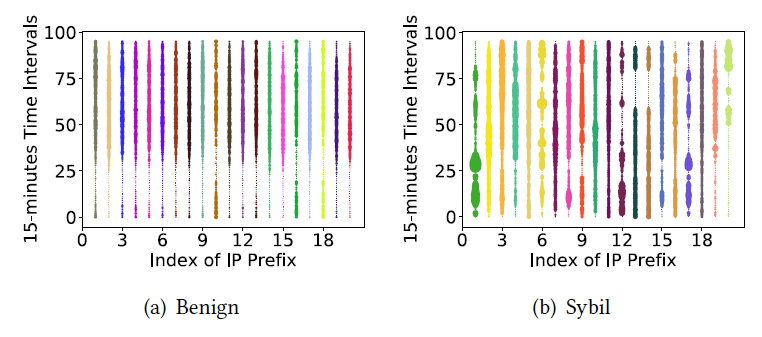
2) Geolocation inconsistency
IP 주소나 전화번호 정보는 위치 정보와도 매핑될 수 있는 정보이다. 데이터셋에서 관측해본 결과 대부분의 sybils들은 동일한 위치에서 가입을 하지 않는 것으로 나타났다.
이는 cloud나 remote compomise machine을 이용하기 때문일 것으로 추측하고 있다.
3) Rare and outdated WeChat and OS versions
데이터셋을 관측해본 결과, 대부분의 sybil accounts 들은 오래된 WeChat 버전이나 OS 버전을 사용하는 것으로 나타나고 있다.
4. Design of Ianus
4.1. Overview
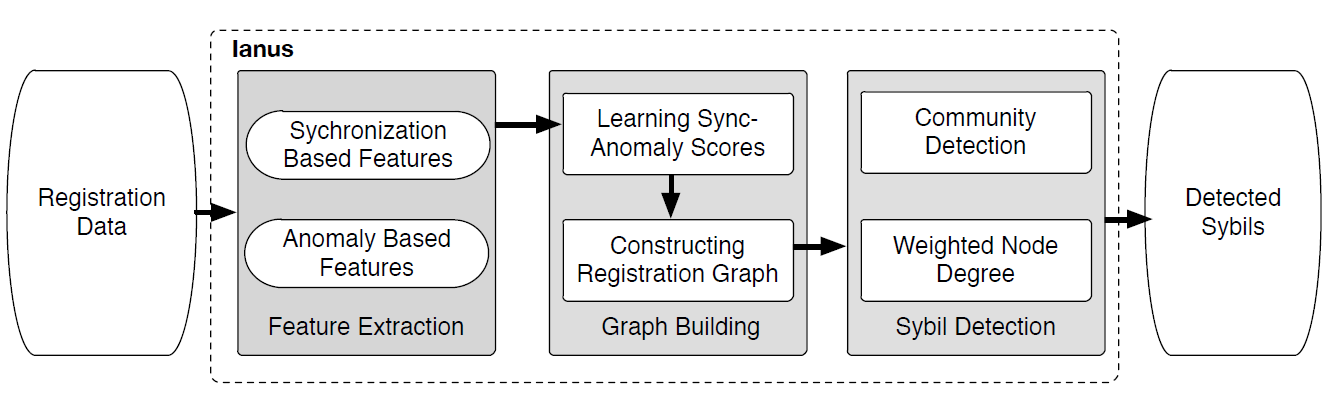
Ianus의 전체적인 구조는 [그림 7]과 같다. Ianus 는 크게 3단계를 거쳐 동작하게 되는데, 1) Feature extraction 2) Graph building 3) Sybil detection 이다.
우선 Feature extration 단계에서는 앞서 3장에서 설명한 measurement 기준에 의거하여 각 attributes에 대하여 Synchronization based features와 anomaly based features를 수집한다.
graph building 단계에서는 weighted graph를 생성하여 heterogeneous 한 features들을 integrate 하는 역할을 수행한다. Sybil Node들은 densly 하게 연결되어 있으며 높은 weight 값을 가지고, benign Node 들은 sparse 하게 연결되어 있으며 낮은 weight 값을 가지게 될 것이다.
각 weight 값을 매기기 위해서 두 account 사이의 synchronized & anomaly 패턴을 기반으로 sync-anomaly score를 측정하였다.
Sybil detection 단계에서는 앞서 생성한 registration graph 를 분석하여 Sybils를 탐지하는 과정이다. 분석에는 community detection 알고리즘과 같은 기법이 적용될 수 있다. 본 논문에서는 community detection 방식과 비슷한 성능을 내지만 훨씬 빠르게 동작하는 simple weighted node degree based method를 제안하였다.
만약 특정 Node의 weighted degree가 threshold 값보다 높으면 sybils 라고 판단하는데, 이 threshold 값은 ML 을 통해 학습될 것이다.
4.2. Extracting Features
앞서 살펴보았듯이 Features로는 synchronization based features와 anomaly based features를 수집한다. synchronization based features들은 2개의 registrations 쌍 사이에서 산출되며, features들은 binary 이다. 예를 들어 registration A와 B사이에 feature 1이 유효하다면 1, 유효하지 않다면 0으로 표현하는 것이다.
반대로 anomaly based features들은 쌍으로 계산하는것이 아니라, 각 노드마다 individual 하게 계산한 뒤, 두개의 registration 각각의 anomaly based feature 값을 concatenate 하는 형태로 합치게 된다.
Synchronization based features는 [그림 8]과 같으며, Anomaly based features 는 [그림 9]과 같다.


4.3. Building a Registration Graph
registration graph의 최종 목표는 accounts로 대표되는 Node 중에서, sybils 의 경우 더 큰 weight 값으로 edge들이 이어지게 만드는 것이다.
각 노드 쌍의 score를 계산하기 위해서는 feature들로부터 ML 학습을 진행하게 된다. 이 socre를 sync-anomaly score라 부르고, 해당 score를 기준으로 registration graph를 생성하게 된다.
sync-anomaly score를 계산할 때 가장 중요한 것은 synchronization based feature와 anomaly based feature의 가중치를 계산하는 것이다. 데이터셋에서 registration 정보와 labels이 포함된 historical 데이터를 통해 학습을 진행하였다.
즉, 제공된 feature값과 label을 통해 logistic regression classifier 모델을 설계했고, 그 결과값을 sync-anomaly score로 산출하였다. 이 때 graph 에서는 두 노드 사이에서 benign인지 sybils 인지 labeling을 해야 한다.
가장 간단하게 labelling 하는 방법은 두 Node의 label을 활용하는 것이다. 만약 한 쌍의 노드에서 둘 다 benign 이라면, 해당 edge를 benign으로 labelling 하고, 둘 다 sybils 하다면 해당 edge를 sybil로 labelling하면 된다.
하지만, 이런 방식은 inconsistency를 일으킬 수 있다. 두 쌍의 Nodes들이 있을 때, randomness에 의해 같은 features를 가진다고 하더라도 다르게 labelling될 수 있다.
이러한 inconsistency는 ML 학습 과정에서 여러 문제를 발생시킬 수 있다. 따라서 본 연구에서는 labelling을 진행할 때, 데이터셋 내에서 모든 가능한 pairs of registration 쌍을 고려한 뒤, labelling을 해주는 것이다.
예를 들어 특정 feature vectors를 가지는 노드 쌍들이 대부분 Sybils 라면 해당 edge를 sybils 라고 labelling 하는 것이다. 이러한 과정을 통해 Sybils 가 아닌 두 노드들은 최대한 densly 연결되지 않도록 구성할 수 있다.
Positive label를 부여하는 threshold값을 높이면, 한 쌍의 benign accounts들이 더 연결되지 않도록 된다. 이제 각 쌍의 노드마다 feature vectors와 label이 준비되어 있다. 이제 이 두 정보를 가지고 sync-anomaly score 를 학습하게 된다.
logistic regression classifier에 input 값으로 feature vecotrs가 들어가고, output 값으로 해당 edge 가 positive label일 확률이 나오게 된다. 해당 확률과 label 값을 통해 학습을 시켜주고 난 뒤, 각 노드 쌍마다 해당 classifier 를 적용시키면 확률값이 output으로 나오게 되고, 이것을 sync-anomaly score로 사용하게 된다.
다시한번 강조하지만 본 장에서의 목적은 sybils 노드 끼리는 densly 연결되게 하고, benign 노드는 최대한 격리시키도록 만드는 graph를 구성하는 것이다. 이를 구현하기 위해서 graph를 그릴 때, 두 노드가 모두 sybils 라고 판단될 경우에만 edge를 그렸다.
즉, 이 말은 두 노드 사이의 sync-anomlay score가 0.5를 넘는 경우에만 edge를 그었고, edge의 weight 로 sync-anomaly score를 사용했다. 하지만, 데이터의 수가 많은 경우 모든 노드 쌍에 대하여 sync-anomaly score를 계산하는 것은 굉장히 어렵다.
따라서 이 문제를 해결하기 위해 registration attributes (IP prefix, phone number, device ID) 가 동일한 노드 쌍에 대해서만 sync-anomaly score를 계산하고, 해당 값이 0.5가 넘을 경우에 edge를 그어주는 식으로 구현하였다. 4.4. Detecting Sybils 앞서 생성한 registration graph를 기반으로 sybils를 탐지하는 단계이다.
sybil accounts들은 densly connected 되어있고 benign accounts 들은 sparse connected 되어있기 때문에, community detection 알고리즘을 적용해볼 수 있으며, 그 중 가장 유명한 Louvain method를 적용해볼 수 있다. 또 다른 방법으로는 simple weighted node degree based method를 적용해볼 수 있다.
weighted degree of a node는 단순하게 해당 노드에 연결된 모든 edge들의 weight 를 더함으로써 계산될 수 있다. 즉, 특정 노드가 다른 노드들과 많이 연결되어 있을수록 sybils 할 확률이 높은 것이다.
하지만, weighted node degree 이 가능한 값은 굉장히 큰 범위를 가지기 때문에, 탐지 정확도를 떨어트릴 수 있다. 이를 해결하기 위해 tanh 함수를 통해 normalize 해주는 과정을 거치게 된다.
이제 이렇게 normalize된 weighted node degree 값을 binary classification classifier 에 적용시킬 수 있는데, 본 연구에서는 앙상블 기법 중 하나인 EasyEnsemble 모델을 사용하였다. 해당 모델을 사용하면 imbalance 한 데이터셋의 문제를 해결해줄 수 있다. (물론 본 연구의 데이터셋이 크게 imbalance 한 것은 아니다만...) 해당 방식으로 실험을 진행해본 결과, Louvain method 와 비슷한 정확도를 뽑아내면서도 훨씬 빠른 성능을 나타내는 것을 확인할 수 있었다.
5. Evaluation
5.1. Experimental Setup
우선 사용된 데이터셋으로는 각 다른 시기에 획득한 WeChat의 2개의 데이터셋을 사용하였다. 앞서 3장에서 획득한 attributes들의 measurments들은 모두 Dataset 2를 사용해 얻어진 결과이다.
또한 sync-anomaly score를 얻는 과정에서도 학습 데이터셋이 필요했다. 이 학습 데이터셋은 Dataset 1 의 일부를 가져와 학습시켰으며, Ianus를 테스트 하는데에는 Dataset 2 를 사용했다.
Ianus 를 evaluation 할 때는 1) variants of Ianus 와 비교하는 method와 2) Popularity-based method 로 나눠 진행하였다. 우선 variants of Ianus로는 Ianus, Ianus-Sync & Ianus-Anomaly(feature로 synchronization or anomaly based feature 하나만 쓰는 방식), Ianus-FS (edge를 그리는 threshold 값 다르게), Ianus-CD (Louvain method 사용), Ianus-FS-CD 등이 있다.
또한 Popularity-based method는 앞서 3.2장에서 본 것처럼 단순히 attributes 의 popularity가 높으면 sybils 라고 판단하는 방식이다.
예를 들어 특정 IP prefix의 popularity가 높으면 이에 해당하는 모든 노드들을 Sybils 라고 판단하는 방식이다.
5.2. Results
1) Ianus is effective
우선 Ianus 를 통해 dataset2를 테스트해 본 결과, 92.4% Precision, 80.2% Recall, 85.9% F-Score를 나타냈다. 이는 Ianus가 효과적으로 sybils 를 탐지하고 있음을 알 수 있다.
또한 registration graph에서 community의 size에 따라서 false positive 비율이 상이하게 나타는 것을 확인할 수 있었다. 대체적으로 community size가 너무 작거나 크면 false positive 비율이 증가하는 것을 확인할 수 있다.
2) Impact of the threshold of Sybil support ratio
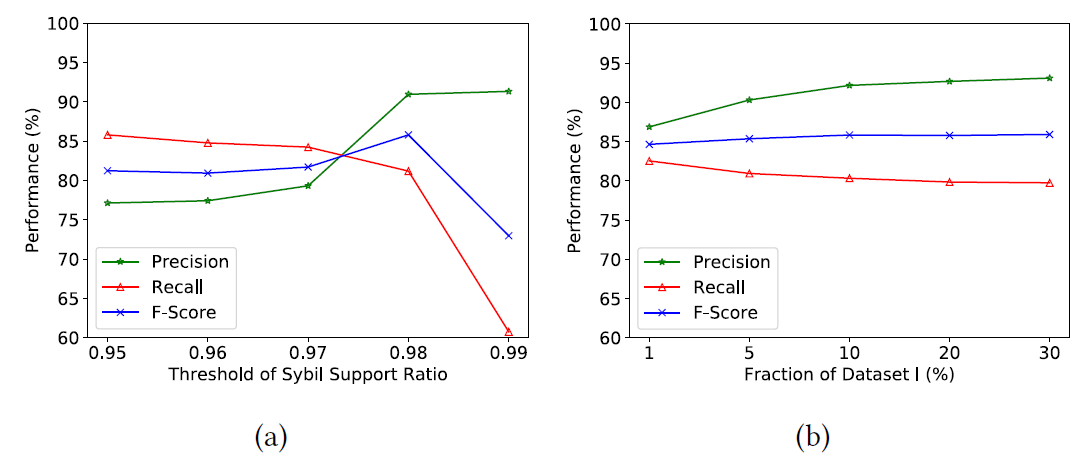
[그림 10]의 a에서 확인할 수 있듯이 threshold of sybil support 가 0.95에서 0.98로 증가할수록 Precision은 증가하고 Recall이 감소하는 것을 확인할 수 있었다.
또한 0.98에서 0.99로 증가할수록 Precision은 조금 증가하지만 Recall이 급격하게 감소하는 것을 확인할 수 있었다. 따라서 본 시스템에서 0.98을 threshold of sybil support로 채택하였다.
3) Impact of the training dataset size
[그림 9]의 b에서 확인할 수 있듯이 dataset 1의 데이터 중 1%를 사용했을 경우에서 10%를 사용했을 경우로 갈수록 Precision이 증가하고 Recall이 감소하는 것을 확인할 수 있었다. 다만, 10%가 넘어서는 stable한 상태에 접어들게 되므로, 굳이 10% 이상의 많은 수의 데이터를 학습과정에 사용할 필요는 없는 것으로 나타났다.
4) Ianus vs Ianus-Sync & Ianus-Anomaly

[그림 11]의 a에서 확인할 수 있듯이 두개의 feature중 하나만 사용하는 것보다 둘 다 사용하는 것이 전체적인 성능에 좋음을 알 수 있다.
왜냐하면 Synchronization based feature와 Anomaly based feature는 서로 complementary 관계에 있기 때문이다.
5) Feature weights
[그림 11]의 b에서 확인할 수 있듯이 Ianus에 사용되는 모든 Features 들은 모두 positive한 weights를 가지고 있다. 즉 모든 features들이 Ianus의 성능(sync-anomaly scores 측정)에 positive한 방향으로 영향을 미친다는 것이다.
이때 OS 버전이라던지, device 정보 들은 공격자들이 쉽게 바꿀 수 있지만, Ianus에 큰 impact를 미치는 features들이다. 따라서 공격자들이 이러한 정보들을 바꾼다면 Ianus 가 우회될 여지가 있긴 하다.
하지만 이러한 쉽게 공격자들이 바꿀 수 있는 features들을 모두 제거하고 IP 기반 features등과 같이 공격자들이 수정하기 어려운 features들만 가지고 Ianus를 구현해도 93.6%의 precision과 45.1%의 recall을 나타낸다.
즉, 이 방식을 채택하면 모든 sybils 를 잡을 수는 없겠지만 정확도는 여전히 높은 수준으로 동작 가능하다.
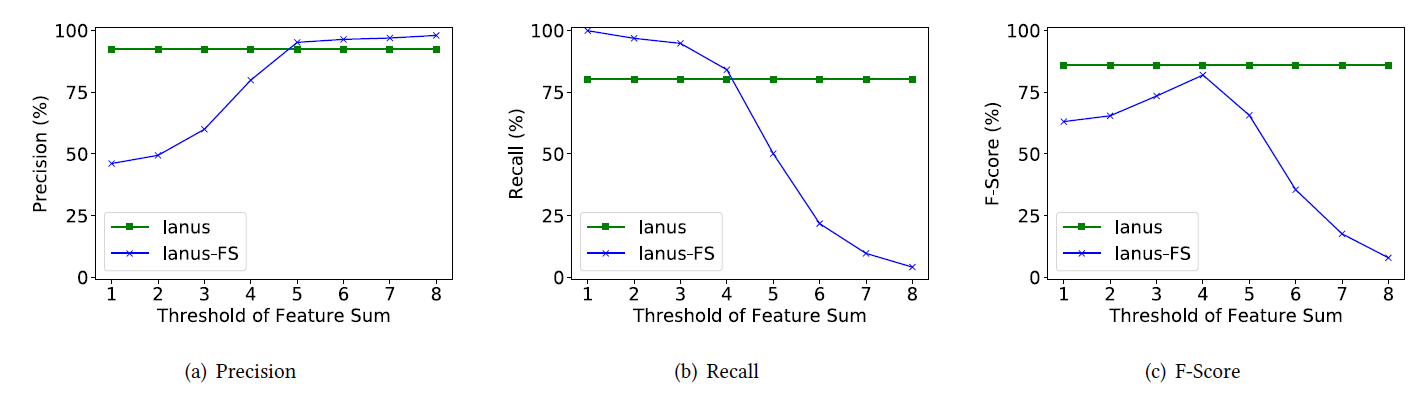
6) Ianus vs Ianus-FS
sync-anomaly score를 기반으로 edge를 그릴때의 threshold 값을 유동적으로 조절할 수 있는 Ianus-FS에서, threshold 값에 따른 성능 변화는 [그림 12]과 같다.
threshold값이 4일 경우, 가장 F-score가 높았으며 Ianus 시스템에 비해서는 4% 정도 낮은 F-score를 기록하였다.
7) Ianus vs Iaus-CD
Louvain method 를 사용하는 Ianus-CD의 경우, [그림 13]에서 볼 수 있듯이 성능적인 면에서는 별 차이가 없지만, 속도적인 면에서 큰 차이가 있기 때문에 Louvain method보다는 weighted node degree based method를 Ianus 에 사용하였다.

8) Ianus vs Ianus-FS-CD
Ianus-FS-CD는 Ianus-FS와 Ianus-CD를 모두 고려한 시스템으로, 총 두개의 threshold 값을 고려하게 된다. feature sum의 값이 4일 경우 가장 성능이 좋았으며, 그 경우 community size의 threshold 변화에 따른 성능은 [그림 14]와 같았다.
Precision은 Ianus에 비해 낮고, Recall은 Ianus에 비해 조금 좋은 것을 확인할 수 있다.

9) Ianus vs popularity-based methods
IP prefix, phone number prefix, device ID attirbutes만을 사용하는 popularity-based methods와 Ianus를 비교한 결과는 [그림 15]와 같았다.
전체적으로 보았을 때, IP prefix를 사용할 경우 성능이 매우 낮았으며, 나머지의 경우 threshold 값을 늘리면 precision은 증가했으나 recall이 급격히 줄어드는 것을 확인할 수 있었다.
종합적인 F-score 지표는 세 시스템 모두 Ianus에 비해 낮은 것을 확인할 수 있었다.

하지만, Ianus와 Phone number prefix, device ID를 사용한 popularity-based methods를 결합한 시스템에서는 [그림 16]와 같이 Ianus와 거의 동일한 precision으로 더 높은 recall과 F-score를 나타내는 것을 확인할 수 있었다. 이는 Ianus와 Phone-Device popularity based methods가 complementary한 관계로 동작할 수 있음을 보여준다.

6. Discussion and limitations
Ianus는 적은 cost로도 바꿀수 있는 features 값을 공격자가 조작함으로써 우회될 수 있다. 하지만, 공격자가 조작하기 어려운 features들로만 시스템을 설계해도 나쁘지 않은 성능을 나타내고 있다.
또한, Ianus는 많은 수의 benign users를 Sybils로 가입하게 모으는 crowdturfing 을 통해서도 Ianus를 공격할 수 있지만, crowdturfing을 막는 방식은 따로 있기 때문에 크게 고려하지 않았다. Ianus는 높은 Precision을 가졌지만 recall은 비교적 높지 않다. 이러한 문제를 해결하기 위해서는 다른 타입의 데이터 (content, behavior 등) 역시 활용해야 할 것으로 예상된다.
7. Conclusion and future work
본 연구에서는 WeChat의 데이터의 synchronized & abnormal 패턴을 통해 Sybils를 탐지하는 Ianus 시스템을 제안하였다. 각 노드 쌍에 대해 synchronization & anomaly features를 추출하였으며, 이를 통해 graph를 building 하였다.
Ianus는 좋은 성능을 가지며, 효과적으로 Sybil attack을 탐지하는 것을 알 수 있었으며, 실제 WeChat에서 해당 시스템을 채택하기도 하였다. 앞으로 본 연구팀에서는 unsupervised Sybil detection based on registration data에 관한 연구를 수행할 예정이라고 한다.
Reference
Dong Yuan, Yuanli Miao, Neil Zhenqiang Gong, Zheng Yang, Qi Li, Dawn Song, Qian Wang, and Xiao Liang, "Detecting Fake Accounts in Online Social Networks at the Time of Registrations." , In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security (CCS '19), 2019



