
shine's dev log
[논문] Modeling Tabular Data using Conditional GAN 본문
논문 제목 : Modeling Tabular Data using Conditional GAN
0. abstract
continuous 와 discrete data가 같이 있는 tabular data를 GAN과 같은 생성 모델을 통해 생성하는 것은 쉬운 일이 아니다. 본 논문에서는 CTGAN이라 불리는 모델의 conditional generator를 통해 이러한 문제를 해결하였으며, 생성모델의 성능을 측정하기 위한 benchmark 시스템 또한 제안하였다.
1. Introduction
최근 deep generative models들이 활발히 연구되면서 확률 분포를 보다 정교하고 정확하게 배움으로써 좋은 성능의 생성 모델들이 나오고 있다.
이런 상황 속에서 이러한 생성모델을 정확하게 evaluation 할 수 있는 benchmarking 방식 또한 중요하게 대두되고 있다.
하지만 tabular data GAN의 경우에 likelihodd fitness 나 machine learning efficacy 등의 metric 에서 좋지 않은 성능을 보여주고 있다.
이러한 한계점은 tabular data 에서 discrete와 continuous한 columns을 학습시킬 때, 다양한 문제들이 발생하기 때문이다. continuous data의 경우 확률 분포가 여러개의 봉우리를 가지게 되는 multi-modal distribution을 가지며, discrete data의 경우 category별로 빈도수가 모두 다르다는 성질(imbalance) 이 존재한다.
이러한 문제점들을 극복하기 위해 본 연구에서는 conditional tabular GAN(CTGAN) 을 제안한다. 즉 mode-specific 하게 데이터를 생성해내는 것이다.
CTGAN을 적용해 테스트해본 결과, 다른 bayesian network나 GAN에 비해 좋은 성능을 내는 것을 확인할 수 있었다.
본 논문의 contributions는 크게 두가지가 있는데, 각각 1) CTGAN을 통해 tabular data를 보다 좋은 성능으로 생성할 수 있는 방법 제안하였으며 2) 데이터 생성 알고리즘에서의 성능을 평가할 수 있는 단일화된 benchmarking 시스템을 제안한다.
2. Related work
이전까지 tabular 데이터에 대한 생성 모델은 데이터의 type에 따라서 제한된다는 한계가 존재했다. 그럼에도 불구하고 의료 데이터에 tabular GAN이 자주 이용되기도 하였다.
3. Challenges with GANs in Tabular Data Generation Task
Tabular data를 생성할때는 Generator G가 기존의 table T을 기반으로 Tsync를 생성하게 된다. T는 Nc개의 continous columns를 가지게 되며, Nd개의 discrete column을 가진다. 각각의 columns들은 random variable로써 joint distribution을 가지게 된다.
이렇게 생성된 Tsync는 크게 두가지 metric으로 평가되게 된다.
1) Likelihodd fitness : Tsync에 있는 columns들이 Ttrain에 있는 columns의 joint distribution을 잘 따르는가?
2) Machine learning efficacy : Ttrain을 통해 만들어진 Tsync를 통해 학습한 ML 모델의 성능과, 실제 데이터인 Ttest를 통해 학습한 ML 모델의 성능이 얼마나 비슷한지?
이러한 metric이 좋은 성능을 내기 위해서는 tabular data에의 Mixed data types(discrete & continuous columns), Non-Gaussian distributions(continuous data의 경우), Multimodal distributions(확률분포가 여러 봉우리 가짐), Learning from sparse one-hot-encoded vectors, Highly imbalanced categorical columns (mode collapse 발생) 등의 문제를 해결해야 한다.
4. CTGAN Model
앞서 설명했듯이 CTGAN에서는 mode-specific normalization이 적용되는데, 이는 데이터의 non-Gaussian 과 multimodal distribution 문제를 해결해준다.
또한 conditional generator와 training-by-sampling이 적용되는데, 이는 imbalanced discrete columns 문제를 해결해준다.
4.1. Notations

4.2. Mode-specific Normalization
tabular 데이터를 생성하기 전에 Normalization 과정을 거쳐줘야 한다.
우선 discrete 변수는 단순히 전체 category 개수만큼의 비트로 one-hot encoding을 진행해주면 된다.
문제는 continuous 변수인데,, 일단 continuous 변수를 가지는 하나의 column이 있다고 생각해보자. 해당 column에 속한 데이터들의 확률분포는 [그림 1]과 같이 여러개의 봉우리(?) 가 있는 모양으로 표현되는 경우가 많다. 이를 Gaussian mixture라고 부른다.
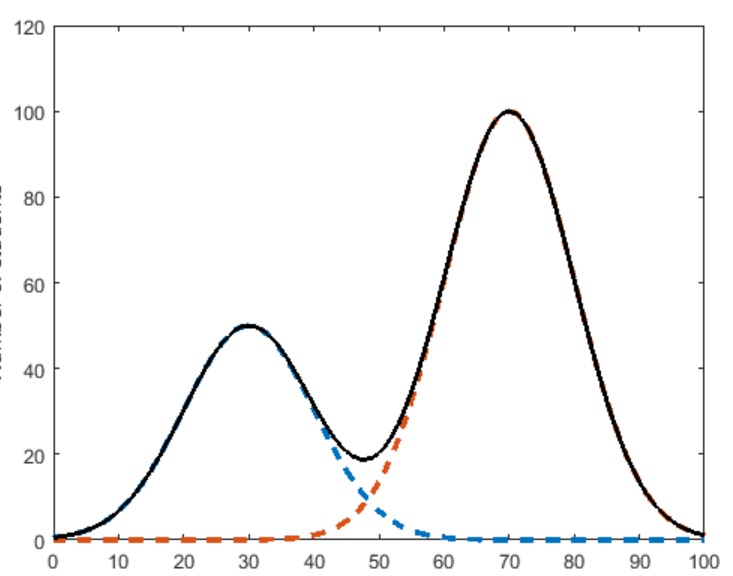
이럴 경우 제대로 데이터를 생성하기 어렵기 때문에 normalization 과정을 거쳐야 한다. 우선 gaussian mixture에서 봉우리 개수만큼의 gaussian 확률 분포를 따르는 여러개의 sub distribution으로 나눠줘야 한다. 이 과정에서 Gaussian mixture model (VGM)이 사용된다.

[그림 2]는 해당 논문에서 model-specific normalization의 예시로 든 사진인데, 해당 예시에서는 총 3개의 sub distribution, 즉 3개의 mode가 존재함을 알 수 있다.
우선 VGM을 통해 sub distribution으로 나눠주고, 이 각각의 sub distribution의 분산과 weight 를 미리 구해두자.
다음으로 i번째 column에 해당하는 데이터인 C(i,j)를 확률밀도함수에 찍어보고, 가장 확률이 높게 나오는 sub distribution을 구해준다.
[그림 2]에서는 3번째 mode에서의 확률이 가장 높게 나오므로, 이를 표현하기 위해 one-hot encoding으로 [0, 0, 1]으로 표현해주었다. 또한 해당 sub distribution의 평균과 표준편차를 통해 scalar로 표현된 가중치값인 알파값 또한 구할 수 있다.
이제 구한 값들을 가지고 [그림 3]과 같이 각 row들을 normalization 해주면 된다.

여기서 d(1,j) 이전의 부분들은 continuous columns 들이고, [그림 2]의 과정을 거쳐 mode-specific 하게 구했다. d(1,j) 이후의 부분들은 discrete columns 들이고 간단히 one-hot encoding 하여 구해주었다.
4.3. Conditional Generator and Training-by-Sampling
이제 normalization 도 마쳤겠다, 본격적으로 GAN 학습을 해볼 것이다.
하지만 몇가지 문제가 있다. Discrete 변수의 경우, 각 category마다 빈도가 다르다.
예를 들어 '색깔'이라는 column은 discrete 변수이다.
실제 table T에서 '색깔' column에 해당하는 row들을 쭉 살펴본 결과 '빨강'에 해당하는 row가 전체 row의 80%를 차지하고 '파랑' 에 해당하는 row가 나머지 20%를 차지한다고 가정해보자.
만약 GAN을 학습시킬때 이러한 빈도를 신경쓰지 않고 학습시키게 되면, 원래 데이터의 특징이 사라지게 된다. 이를 해결하기 위해 'Training-by-sampling' 이라는 개념을 도입하였다.
Training-by-sampling은 다음과 같이 진행된다.
1) 우선 N_d 개의 discrete columns 중에 랜덤으로 하나를 선택한다. 이를 i* 라 표현한다.
2) 위에서 선택된 column에 대해 PMF(확률 질량 함수)를 구한다.
3) PMF를 따르는 확률 분포에 따라 값 하나를 선택한다. 이를 k* 번째 값이라 표현한다.
4) 이제 Conditional vector를 i*와 k* 값을 고려하여 생성해준다.
[그림 4]는 본 논문에서 CTGAN의 전체 과정을 나타낸 그림이다.
[그림 4]의 예시에서는 discrete column 중 2번째 column이 선택되었으므로 i*의 값은 2다. 또한 2번째 column중 1번째 value가 선택되었으므로 k*의 값은 1이다.
따라서 [00010]으로 표현되는 conditional vector를 생성할 수 있게 된다.
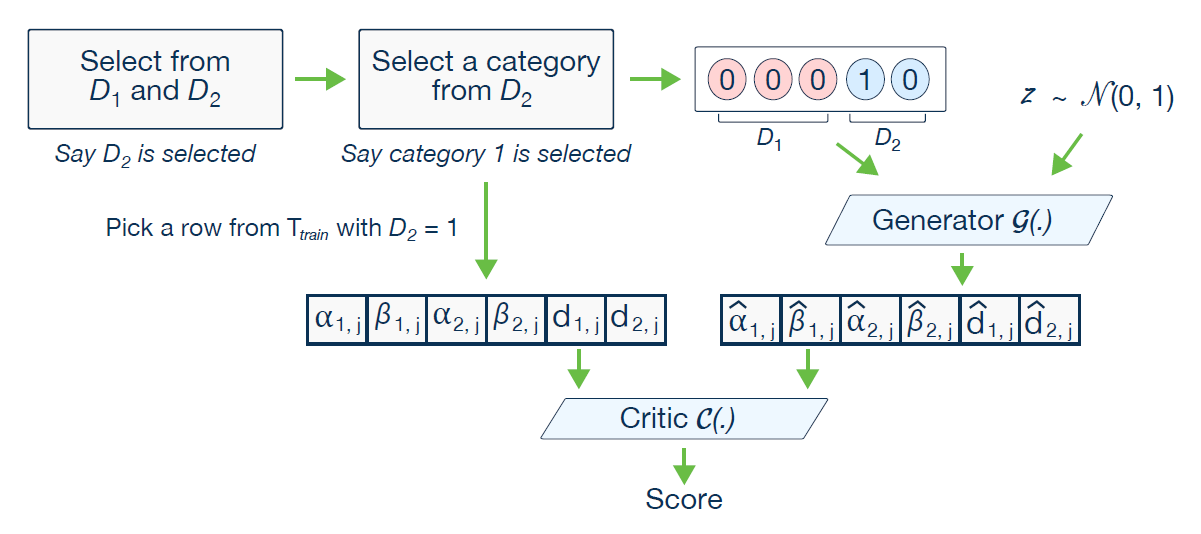
이렇게 taining-by-sampling 을 통해 학습을 진행할 경우, discrete column에 대하여 각 category 별로 기존 데이터의 빈도와 비슷하게 학습이된다.
4.4. Network Structure
앞서 말한 내용들을 모두 정리하여 만든 generator 의 구조는 [그림 5]와 같다.
latent vector 에서 시작하여 2개의 hidden layer를 거치고 난 뒤, 알파, 베타, d 의 값을 구하게 된다.
알파값은 scalar 값이므로 activation 함수로 tanh 를 사용하였고, 베타와 d는 벡터 형식의 데이터이므로 다중 class 에 대한 classification이 가능한 gumbel sofmax 함수를 사용하였다.
학습에 사용된 loss는 Generator loss로, one-hot encoding된 벡터 m과 d 사이의 cross-entropy loss를 사용하게 된다.

또한 discriminator (여기에서는 critic) 의 구조는 [그림 6]과 같다.
discriminator는 mode collapse를 막기 위해 10개의 sample이 한번에 들어가게 되며, 10개의 conditional vector도 함께 들어가게 된다. (PacGAN 구조 사용)
결국 마지막 레이어에서는 1개의 노드만이 남게 되며 real 데이터라면 1, fake 데이터라면 0으로 예측하게 된다. 학습에는 WGAN loss가 사용되며 optimizer로는 Adam이 사용된다.

4.5. TVAE Model
GAN 뿐 아니라 VAE에도 해당 방식을 적용할 수 있다. 구조는 [그림 7]과 같다.
나머지는 모두 전체적인 구조는 거의 모두 같고, cross entropy를 사용했던 generator loss와 다르게 ELBO loss를 사용했다.
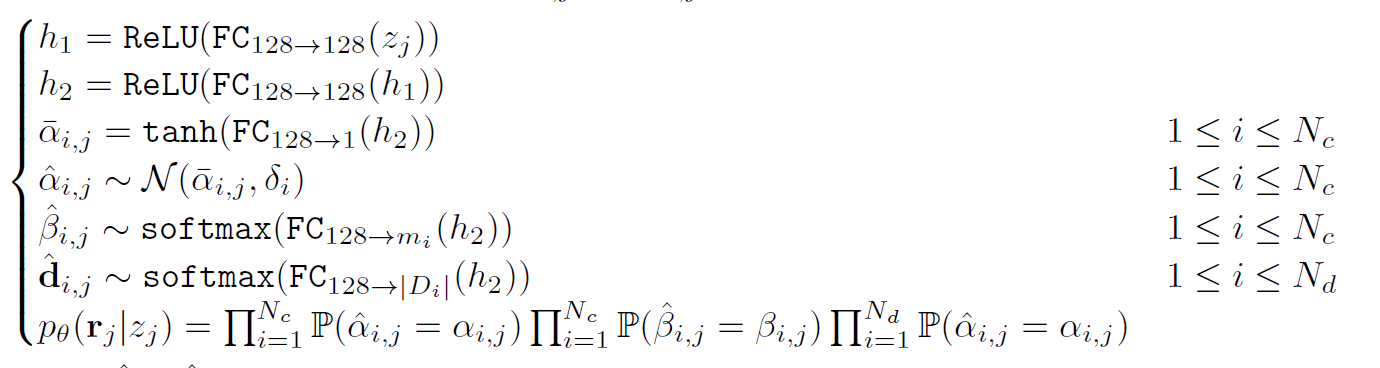
5. Benchmarking Synthetic Data Generation Algorithms
5.1. baselines and Datasets
본 논문에서 제안하는 데이터 생성 알고리즘에 대한 benchmark 시스템에서 기반으로 사용되는 baselines는 Bayesian networks(CLBN, privBN)와 딥러닝을 사용한 synthetic data generation (MedGAN, VeeGAN, TableGAN) 등이 있다.
본 benchmark에 사용되는 데이터셋은 크게 두가지로 분류할 수 있다.
1) Simulated data
실제 데이터로부터 오라클 S를 통해 simulate된 데이터이다. Gausian mixture 모델을 사용해 simulate한 Grid, Ring과 Bayesian network 모델을 사용해 simulate한 alarm, child, asia, insurance 데이터셋이 있다.
이렇게 simulate한 데이터셋의 경우 실제 해당 데이터셋의 실제 분포를 정확하게 알 수 있다는 특징이 존재한다.
2) Real data
실제로 존재하는 데이터셋도 사용하였다. UCI ML repository에서 6개의 자주 사용되는 데이터셋을 선정하였으며, MNIST 데이터셋을 기반으로 MNIST28, MNIST12 데이터셋도 선정하였다.
5.2. Evaluation Metrics and Framework
이제 본 논문에서 제안하는 두가지 metric 을 하나씩 살펴보자.
- Likelihood fitness metric
Likelihood fitness metric 에서는 앞서 설명한 두가지 데이터셋 타입 중, Simulated data를 사용하게 된다.
[그림 8]은 Likelihood fitness metric를 구하는데 사용된 framework를 나타낸 것이다.

우선 Simulated된 데이터를 Train 과 Test로 나누고, Test 데이터를 생성모델을 통해 synthesize한다. 이 Synthetic data와 기존에 Simulated 된 데이터 사이의 유사도 likelihood를 구하면 L(sync) 가 나오게 된다.
하지만 L(sync)는 생성 모델이 overfitting될수록 잘 나오기 때문에, 이를 피하기 위해 Test데이터와 synthesize 데이터 사이의 likelihood를 구한 L(test)도 사용하게 된다.
- Machine learning efficacy
Machine learning efficacy 에서는 앞서 설명한 두가지 데이터셋 타입 중, Real data를 사용하게 된다.
[그림 9]는 Machine learning efficacy를 구하는데 사용된 framework를 나타낸 것이다.

실제 데이터셋의 Train 부분을 통해 생성된 Synthetic Data를 기반으로 다양한 ML 모델(DT, SVM, MLP)을 학습시킨 결과와, 실제 데이터셋의 Test 부분을 기반으로 동일한 ML 모델을 학습시킨 결과와의 성능 차이를 비교하면 된다.
5.3. Benchmarking Results
이렇게 두가지 metric을 기반으로 실험을 진행한 결과는 [그림 10]과 같다.
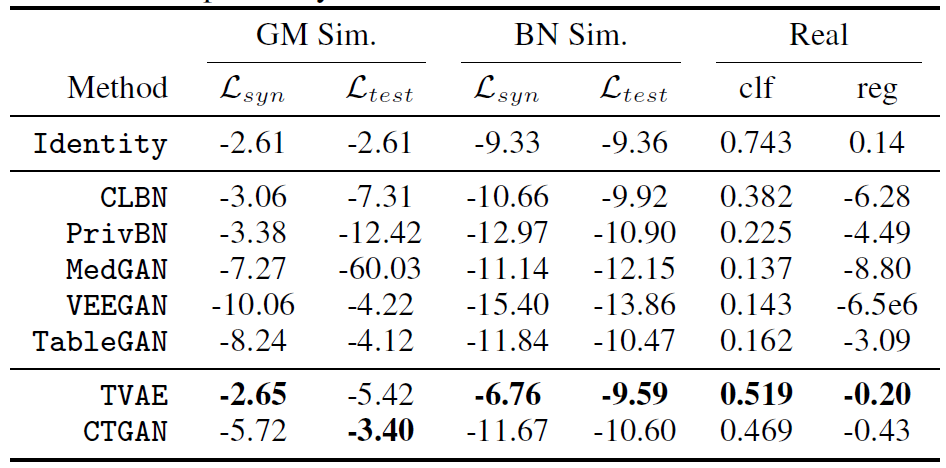
GM Sim과 BN Sim 은 각각 Likelihood fitness metric에서 사용된 simulated data가 Gaussian mixture simulated data와 Bayesian network simulated data를 사용했을 때 측정한 L(sync)와 L(test)를 나타냈으며, Real 항목은 Machine learning efficacy metric에서의 성능 지표를 나타낸다.
전체적으로 본 논문에서 제안한 TVAE와 CTGAN이 좋은 성능을 내는 것을 볼 수 있다.
하지만 TVAE의 경우 직접적으로 실제 데이터를 통해 generator를 학습시키고, GAN의 경우 Discriminator를 통해 간접적으로 generator를 학습시키기 때문에, Privacy 등의 보안 이슈가 있는 경우 CTGAN을 이용하는 것이 더 좋은 선택지가 될 수 있다.
5.4. Ablation Study
Ablation study는 본 논문에서 제안한 기능을 하나씩 제거해보면서, 해당 기능이 성능향상에 도움이 되었음을 증명하는 방법이다.
[그림 11]과 같이 본 논문에서 제안한 기능에대한 Ablation study를 수행한 결과, Mode-specific Normalization, conditional generator & training-by-sampling, Network architecture 등 모든 기능이 CTGAN의 성능을 향상시킨 것으로 나타났다.

즉, Tabular 데이터를 synthesize 하는 과정에서 CTGAN에서 소개한 기법들이 큰 도움을 준다는 것이다.
6. Conclusion
본 논문에서는 discrete / continuous data가 혼재되어있는 tabular data에서 데이터를 생성하는 CTGAN을 제안하였다.
Mode-specific normalization을 통해 중구난방의 분포를 가지던 continuous 값을 NN 학습에 최적화된 형태로 normalize 하였으며, conditional generator와 training-by-sampling 을 통해 학습과정에서의 imbalance data 이슈를 해결하였다.
Reference
Lei Xu, Maria Skoularidou, Alfredo Cuesta-Infante, Kalyan Veeramachaneni, "Modeling Tabular data using Conditional GAN" , NIPS'19, 2019



