
shine's dev log
[논문] Detecting Credential Spearphishing Attacks in Enterprise Settings 본문
논문 제목 : Detecting Credential Spearphishing Attacks in Enterprise Settings
0. Abstract
본 논문에서는 enterprise 환경에서 credential spearphishing 공격을 탐지하는 새로운 방안을 제시한다.
제안된 시스템에 사용된 feature는 spearphishing 공격의 특징을 반영한 feature를 사용하며, 새로운 non-parametric anomaly scoring technique 기술과 결합하여 사용한다.
본 시스템을 수년간 수집된 수신 이메일 데이터셋에 적용하여 평가한 결과, 다양한 spearphishing 공격을 탐지할 수 있었으며, 또한 본 시스템의 FP rate가 매우 낮아 실용적이며, 기존의 방법보다 훨씬 낮은 수의 alert generation 을 가지고도 탐지할 수 있다는 장점이 있다.
1. Introduction
Spearphishing 공격은 특정 집단을 목표로 수행하는 공격으로, 굉장히 정교하게 접근하고 공격하므로 이를 탐지하거나 예방하는 것이 매우 어렵다.
Spearphishing 공격은 다양한 형태로 존재한다. 가장 대표적인게 악의적인 첨부파일을 보내는 방식인데, LBNL(Lawrence Berkeley National Laboratory) 의 데이터셋에 따르면, 첨부파일을 통한 Spearphishing 사례는 거의 존재하지 않는다. 대신에 Credential Spearphishing이라 불리는 방식으로 많이 공격하고 있다.
Credential Spearphishing은 메일을 통해 허위 링크를 보내고, 허위 사이트에서 IP/PW와 같은 credential 정보를 입력하도록 유도하는 공격방법이다.
그래서 본 연구에서는 enterprise 환경에서 Credential Spearphishing 공격을 탐지하는 시스템을 제안하려 한다.
그런데 큰 문제가 하나 있다. 본 연구팀이 가진 데이터셋은 3억7천만 개의 이메일 데이터를 가지고 있지만, 그 중 10개정도만 sphearphishing 이메일이다.
즉, 데이터셋의 label이 너무 불균형해서 FP rate이 높아진다는 문제가 생긴다. 만약 0.1%의 FP rate을 가진다고 해도, 370,000개의 잘못된 경고 알람이 울릴 것이다. 또한, training 과정에서도 데이터의 label이 불균형하므로 학습이 잘 안될 가능성이 높다.
이를 해결하기 위해 두가지 key contribution 을 제안하였다.
contribution 1) Spearphishing 공격의 기본이 되는 characteristic analysis 를 제안한다. 이를 통해 성공적인 Spearphishing 공격의 여러 단계를 나타내주는 일련의 특징을 도출한다.
contribution 2) 단순하면서도 새로운 anomaly detection technique (called DAS)를 제안한다. DAS는 라벨링된 데이터가 필요 없고, non-parametric 한 형태로 동작한다.
이 두가지 아이디어를 가지고 본 연구팀에서는 실시간 Spearphishing 탐지 시스템을 제안할 것이다.
실제 LBNL의 데이터셋을 가지고 평가해본 결과, 제안 시스템은 하루에 평균 10개 이하의 경고 알림을 보냈으며, 한달치 분석을 15분 내에 완료할 수 있었다.
또한 알려진 Spearphishing 공격 뿐 아니라 알려지지 않은 Spearphishing 공격도 탐지하는 등 좋은 성과를 보였다.
2. Attack Taxonomy and Security Model
Spearphishing 공격은 불특정다수를 목표로한 공격이 아니라, 특정 조직에서 특정 권한을 가진 사람을 대상으로 공격한다. 본 연구에서는 특히 기업을 대상으로한 Spearphishing 공격을 대상으로 연구를 진행한다.
- Attack Stage
1) Lure stage : 공격자가 이메일 수신자들에게 자신들의 존재를 믿을만한 사람이라고 속이는 단계
2) Exploit stage : 이메일 수신자가 공격자를 위해 dangerous 한 행위를 수행하는 단계 (가짜 웹사이트에 credential 정보 입력 등)
- Threat Model
공격자는 기업의 구성원에게 이메일에 포함된 URL 등을 클릭하도록 유도하는 등의 방법을 사용할 것이다. 이 과정에서 공격자는 정상적인 사용자인 척 하려고, 이메일 header field 를 조작할 것이다.
이를 위해 아래 [그림 1]의 조작 방법 중 밑에서부터 3가지 방법을 사용할 것이다. (기업이 DKIM/DMARC 등의 통해 address spoofing은 피할 수 있으므로)

- Security Goal
1) 우선 detector는 매우매우 낮은 FP rate를 유지해야한다.
2) 실제 spearphishing 공격은 무조건 탐지해야 한다. (True Positive)
3. Datasets
본 연구에 사용된 데이터셋은 NBNL 에서 제공된 SMTP logs, NIDS logs, LDAP logs 3가지다.
privacy 이슈를 해결하기 위해 개인정보는 모두 keyed hash 등의 방법으로 익명화하였고, 메일의 bodies / webpages는 포함하지 않도록 하였다. 아래 [그림 2] 는 사용된 데이터셋에 정보를 나타내고 있다.
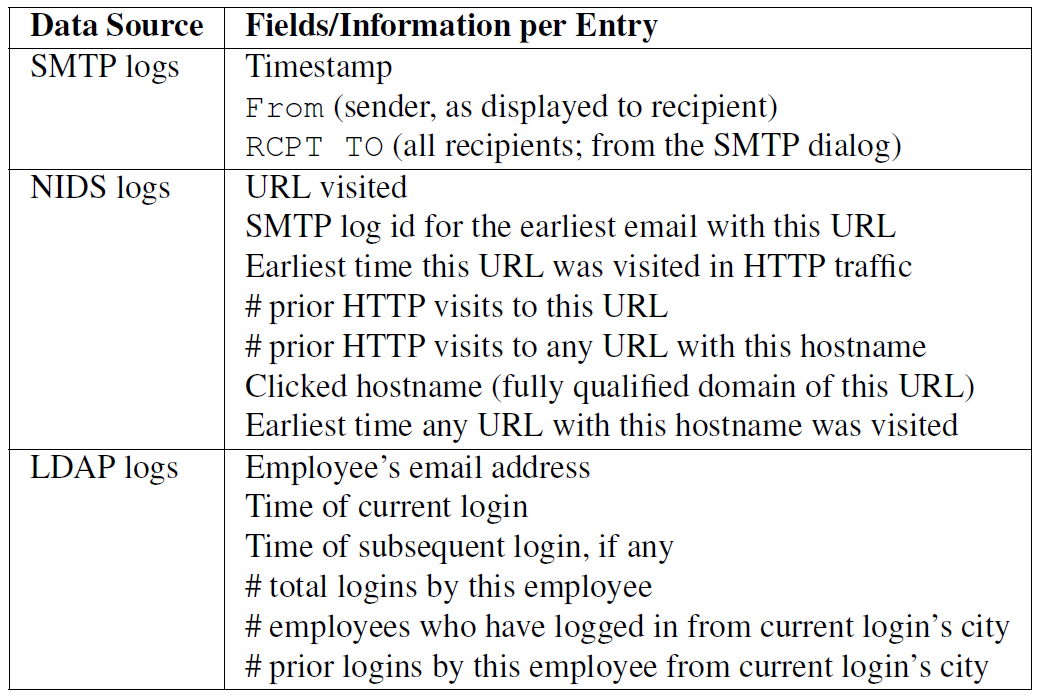
간단히 살펴보면,
SMTP logs를 통해 송/수신된 메일들의 시각과 송/수신지 정보를 확인할 수 있으며,
NIDS logs를 통해 request 된 URL의 정보, 메일에 포함된 URL 주소 정보, 이전 접속 기록 등을 확인할 수 있으며,
LDAP logs를 통해 회사 구성원의 로그인 정보, 이전의 로그인 정보, IP 주소 정보, 구성원 이메일정보 등을 확인할 수 있다.
4. Challenge: Diversity of Benign Behavior
기존의 spearphishing 탐지 ML 모델은 이메일의 header / body에 포함된 내용을 바탕으로 탐지를 하였다. 하지만, 이럴 경우 FPR이 너무 높아진다는 문제점이 발생한다.
본 장에서는 spearphishing 탐지를 어렵게 만드는 다양한 요인들 (특히 정상적인 behavior가 너무 다양하다는 문제점) 에 대하여 알아보도록 한다.
4.1. Challenge 1: Senders with Limited history
메일 송신자의 기록이 존재한다면, 이전의 기록을 통해 spearphishing을 탐지할 수 있지만, 이전에 한번도 송신한 적 없는 송신자가 보낸 메일의 경우 이를 판단하는 것이 쉽지 않다.
본 연구에 사용된 데이터셋에 따르면 40% 정도의 메일이 이전에 송신 기록이 없는 송신자로부터 온 메일이었다.
따라서 단순히 이전에 송신 기록이 없는 송신자를 대상으로 alert 하는 시스템을 만들면 너무 자주 alert 가 울릴 것이고, practical 하지 않다는 문제가 발생한다.
4.2. Challenge 2: Churn in Header values
같은 사용자라고 하더라도, 다양한 메일주소(Header 값) 을 통해 메일을 보내기 때문에, 특정 header 값만을 통해 spearphishing을 판단하는 방법은 FPR이 너무 높다.
예를 들어 같은 학생이더라도, 개인 메일/학교 메일/인턴 회사 메일 등 다양한 메일을 사용할 수 있기 때문에 발생하는 문제점들이다.
이전의 연구에서는 메일 body의 문체를 feature로 포함시켜 spearphishing을 탐지하는 방안을 제안하였지만, 이 방법 역시 FPR 이 너무 높아진다는 문제가 발생한다.
5. Detect Design
본 논문에서 제안하는 탐지 시스템은 [그림 3]과 같은 구조를 가지고 있다.
크게 3단계로 이루어져 있는데, 1) feature extraction stage 2) nightly scoring stage 3) real-time alert generation stage 로 이루어져 있다.
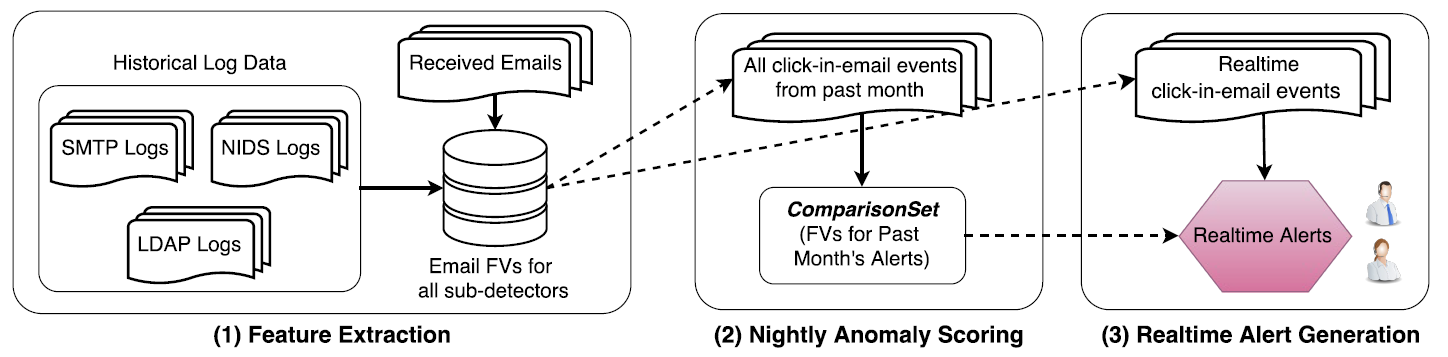
해당 시스템을 구현하는데 사용된 key idea는 다음과 같다.
key idea 1)
앞서 살펴본 attack taxonomy의 2개의 핵심 공격단계(Lure stage, Exploit stage) 를 저격할 2개의 세트로 구성된 reputation-based features 사용
key idea 2)
unsupervised anomaly detection 방식을 통해 스스로 unlabeled events에 위험도를 rank 하여 의심스러운 event를 탐지
5.1. Features per attack stage
앞서 설명했듯이, attack taxonomy의 2가지 공격단계 (Lure stage, Exploit stage) 를 각각 target 으로 한 두개의 feature set을 생성한다.
따라서 생성된 feature은 크게 두가지 classes 를 가지게 된다. 1) domain reputation features (Exploit stage) 와 2) sender reputation feature (Lure stage)
우선, domain reputation feature의 경우를 살펴보자.
spearphishing 공격은 특정한 대상을 목표로 하기 때문에, 공격자가 악의적으로 만든 URL link는 이전에 다른 사용자들로부터 방문된 적 없는 굉장히 rare한 link 일 것이다.
따라서 각각의 click-in-email 이벤트에 대하여, domain reputation features는 employee가 해당 링크를 방문할 확률을 구한다.
다음으로, sender reputatation feature의 경우를 살펴보자.
해당 feature는 sender가 impersonation(변장한) 사용자인지 판단하는 impersonation model을 통해 생성된다. 이때 impersonation 하는 방식은 [그림 1]에서 보았던 아래 3가지 방식을 사용할 수 있으므로, 이를 각각 탐지하는 impersonation model을 사용하게 된다.
5.2. Features
spearphishing 탐지에 사용되는 sub-detector들은 각각 4개의 scalar values를 가지고 있는 feature vector를 사용한다. 4개 중 2개는 doman reputation feature 이며, 나머지 2개는 sender reputation feature 이다.
- Domain reputation features (2개 feature 사용)
- 첫번째 feature : NIDS logs를 통해 이메일에 포함된 link (=FQDN; Fully Qualified Domain Name)를 해당 회사 내에서 클릭한 횟수를 feature로 사용한다. 적게 클릭되거나 아예 클릭된 적이 없을수록 suspicious 하다고 볼 수 있다.
- 두번째 feature : 클릭된 link의 FQDN에 처음 방문한 시각과 클릭된 link의 이메일이 LBNL에 처음 도착한 시각 사이의 시간
- Sender reputation features (2개 feature 사용)
Sender reputation features와 같은 경우, Sender가 impersonation 하는 방식에 따라 수집하는 feature가 달라진다. 따라서 각각의 방식마다 sub-detector를 사용해 따로 feature를 추출한다.
Name Spoofer 방식을 통해 impersonation 하는 경우, 1) 동일한 이름과 이메일 주소로 메일이 온 횟수와 2) 해당 이름의 신뢰도를 feature로 사용한다.
여기서 신뢰도란, 일주일간 한번이라도 메일이 온 적이 있는 주수를 나타낸다. 즉 지속적으로 메일이 계속 주고받았다면, 신뢰도가 높은 것이다.
Previously Unseen attacker 방식을 통해 impersonation 하는 경우, 탐지하기가 힘들기 때문에, 얼마나 자주 사용하지 않는가를 기준으로 본다. 따라서 1) 이전에 해당 이름으로 메일을 보낸 횟수와 2) 이전에 해당 이메일 주소로 메일을 보낸횟수를 feature로 사용한다.
Lateral Attacker 방식을 통해 impersonation 하는 경우, compromised 된 메일을 통해 악의적인 링크를 보내는 공격이다. 이 경우 LDAP logs를 통해 해당 계정이 로그인 되어있는 시간/위치 정보를 활용한다. 따라서 1) 보내진 메일의 위치에 있는 employee들의 명수와 2) 보내진 메일의 위치에 로그인한 history 의 총 횟수를 feature로 사용한다.
5.3. Limitations of standard detection techniques
기존의 탐지 기술은 1) 직접 threshold 값을 수작업으로 정해야 해서 부정확하다는 문제점과 2) supervised learning 방식은 본 연구에서는 dataset이 imbalance 하기 때문에 부적절하다는 문제점과 3) 일반적인 standart anomaly detection 방식은 일부분의 feature 만 가지고 판단하거나, 부정확하다는 문제점 4) parameter를 직접 정해줘야 한다는 문제점들이 존재한다.
5.4. Directed Anomaly Scoring (DAS)
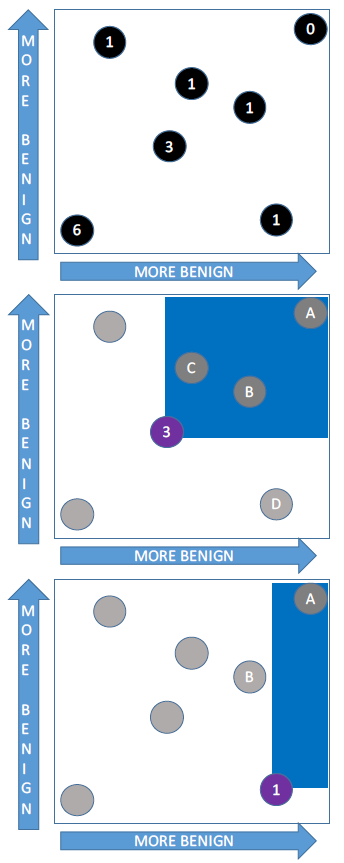
이러한 기존의 문제점들을 해결하기 위해 본 연구팀에서는 DAS(Directed Anomaly Scoring) 라고 불리는 시스템을 제안하였다. 해당 제안 시스템의 전체적인 알고리즘은 [그림 4]와 같다.

DAS의 동작과정은 크게 두가지로 구분할 수 있다.
STEP 1) 모든 events E에 대하여, E의 feature vector 값을 기반으로 위험도를 scoring 한다.
이때 [그림 4] 에서 알 수 있듯이, 만약 E를 제외한 모든 이벤트 X에 대하여, 한 X의 feature가 모든 dimension에서 E보다 malicious 하지 않다고 판단되면 E 의 score 를 하나씩 올리게 된다.
아래 [그림 5]의 세번째 그림을 보면, 보라색 event는 B event에 비해, y축 관점에서 더 malicious 하지만, x축 관점에서는 더 benign 하므로, B event는 보라색 event의 socre를 올리지 못한다.
따라서 오직 A의 event 가 보라색 event의 score를 올리므로 score가 1인 것이다.
STEP 2) 모든 events에 대하여, scoring 값을 기준으로 정렬하여 N 개의 가장 위험한 event를 output으로 리턴한다.
이때 N 값은 보안 담당자가 결정할 수 있는 일종의 hyperparameter 값이다.
5.5. Real-time detection architecture
실시간으로 감지된 spearphishing 위험 정보를 alert 하기 위해, 회사에서 발생하는 모든 email events를 수집하고 30일동안 매일 DAS 시스템을 통해 가장 위험한 N개의 events를 모은다. (30 x N) 이렇게 완성된 events set을 ComparisionSet이라 한다.
이제 실시간으로 오는 이메일과 ComparisonSet을 비교함으로써 alert 를 실시간으로 보낼 수 있게 된다.
6. Evaluation and Analysis
본 연구팀에서는 379M 개의 NBNL 데이터셋을 가지고 성능을 측정하였다.
또한 하루에 alert 되는 횟수를 10개로 설정하였는데, name spoofer, previously unseen attacker에 해당하는 sub-detector에 4개씩 alert 를 할당하였고, lateral attacker 에 해당하는 sub-detector에 2개의 alert를 할당하였다.
6.1. Detection Results: True positive
실제 spearphishing 공격을, malicious 하다고 판단하는 TPR 의 성능을 측정해본 결과 [그림 6]과 같은 결과를 얻을 수 있었다.

그래프에서 볼 수 있듯이, 총 19개의 spearphishing 공격 중에서 17개를 탐지하여 89% 의 TPR을 획득할 수 있었다.
6.2. False Positives and Burden of Alerts
spearphishing 공격이 아님에도 공겨깅라고 판단하는 FPR 의 성능을 측정해본 결과, 0.004%의 FPR 을 나타내는 것을 보였다.
또한, 단순히 spearphishing 공격만 탐지한 것이 아니라, 일반적으로 사용되는 phishing 공격 또한 감지한 것을 알 수 있었다.
6.3. Anomaly Detection Comparisons
앞서 본 연구팀에서 제안한 DAS 기술을 기존의 anomaly detection 시스템과 비교해보았다.
비교에 사용된 3가지 ML anomaly detection 시스템은 각각 KDE(Kernel Density Estimation), GMM(Gaussian Mixture Models), kNN(k-Nearest Neighbors) 이다.
해당 모델과 비교를 위해 동일한 조건으로 training/evaluation을 진행하였다.
해당 모델들을 이용하여
1) 동일한 real-time detector의 alert budget을 가지고 탐지된 공격의 개수와
2) DAS 방식을 이용하여 탐지할 수 있는 만큼의 공격을 탐지하기 위해 사용해야하는 alert budget의 양을 계산하였다.
이때 각 모델에 사용한 hyperparameter는 각각의 성능이 가능한 가장 좋게 될 놈들로 정해주었다.
이렇게 비교한 결과는 아래 [그림 7]과 같다.
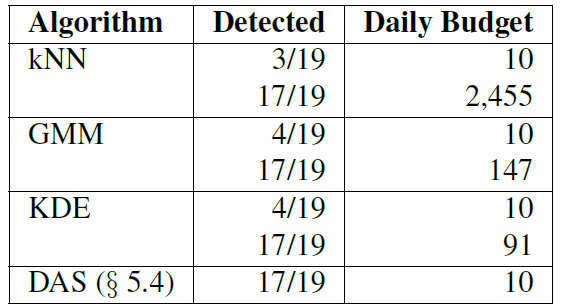
그림에서 볼 수 있듯이 기존의 anomaly detection 시스템은 DAS 에 비해 25% 정도 낮은 성능을 보였으며, DAS가 탐지한 공격을 모두 탐지하기 위해서는 엄청난 양의 alert budget 이 필요함을 알 수 있다.
[그림 8]을의 오른쪽 그래프를 보면 KDE 모델의 sender reputation feature를 보여주는데, 해당 그림이 왜 기존의 시스템의 성능이 낮은지를 보여준다.

[그림 8]의 오른쪽 위에 잔뜩 찍혀있는 점들은 LNBL 근처에 거주하는 employee들이 접속한 기록이지만, KDE는 anomal하다고 판단하였으며, 가운데 왼쪽에 찍혀있는 점들은 다른 employee들은 자주 접속하지 않지만, 과거에 자주 접속했던 기록인데, KDE는 역시 anomaly 하다고 판단하였다.
즉, 기존의 기술들은 여러 dimension 에서의 anomaly를 판단하지 않고 한가지 dimension에서만 판단하여 FPR 이 높게 나온 것으로 해석된다.
7. Discussion and Limitaions
본 제안된 시스템에는 여러가지 한계점들이 존재한다.
1) Limited Visibility
HTTPS 프로토콜을 사용하거나, 외부에서 행해지는 트래픽에 대해서는 탐지할 수가 없다.
2) False Negatives and Evasion Strategies
하루에 정해진 alert 개수가 있으므로, 만약 하루에 여러개의 공격이 수행되면 놓치는 부분이 발생할 수 있다. 또한 employee가 자주 방문하는 웹사이트를 compromising 함으로써 공격을 수행할 수도 있다.
이는 DAS scoring 알고리즘에서 suspicious 한 기준을 dimension 차원에서 좀 더 정교하게 가다듬음으로써 해결될 수 있을 것이다.
8. Related work
기존의 spearphishing을 탐지하려는 연구는 과거 sender의 기록이 없을 경우, 공격을 탐지하는 것이 어려웠다.
또한 기존의 연구들은 FPR이 1% ~ 10% 정도로 매우 높았다. 이에 반해 본 연구는 1% 이하의 FPR 을 유지함으로써 실제 상황에서 실용적으로 사용될 수 있도록 설계하였다.
9. Conclusion
본 연구에서는, real-time detector of identifying credential spearphishing attacks in enterprise settings 을 연구하고 구현하고 평가하였다.
핵심이되는 두가지 내용은 1) 2개의 fundamental한 단계를 거친 공격을 탐지하기 위한 feature를 설정 하였으며, 2) labeled training data 없이 효과적으로 anomaly detection을 수행할 수 있도록 설계하였다는 점이다.
그 결과 370M 개의 데이터에서 0.005% 이하의 FPR 을 유지하며 spearphishing 공격을 탐지할 수 있었다. 또한, 기존의 anomaly detection system은 DSA 와 동일한 수준의 공격을 탐지하기 위해 훨씬 많은 FP 를 발생해야 하므로, 본 모델의 효율성을 확인할 수 있다.
이렇게 본 시스템의 낮은 FPR과 알려지지 않은 spearphishing 공격 또한 탐지하는 성능을 활용하여 실제 NBNL에서는 본 탐지 시스템을 활용하고 있다.
Reference
Ho, Grant, et al. "Detecting credential spearphishing in enterprise settings." 26th {USENIX} Security Symposium ({USENIX} Security 17). 2017.



