
shine's dev log
[논문] Neural Network-based Graph Embedding for Cross-Platform Binary code similarity detection 본문
[논문] Neural Network-based Graph Embedding for Cross-Platform Binary code similarity detection
dong1 2021. 12. 3. 17:34논문 제목 : Neural Network-based Graph Embedding for Cross-Platform Binary code similarity detection
0. Abstract
cross-platform binary code similarity detection은 서로 다른 플랫폼에서 온 서로 다른 두 binary의 similarity를 비교하는 것이 목표이다.
많은 보안 어플리케이션 (표절 탐지, 멀웨어 탐지, 취약점 검색 등) 이 있는데, 이러한 어플리케이션들은 주로 approximate graph-mathing 알고리즘 이용해 탐지한다.
하지만, 너무 느리고, 부정확하며, 새로운 task에 적용하기 어렵다는 단점이 존재한다.
이러한 문제를 해결하기 위해 본 연구에서는 새로운 neural-network 기반의 Graph Embedding 방식을 사용한 "Gemini" 를 구현하였다.
이 방식은 각 binary function의 control flow graph를 기반으로 embedding (numeric vector) 을 진행한 후, 두 function의 distance를 비교함으로써 similarity를 비교하는 방법이다.
Gemini는 최근 다양한 접근 방법과 비교해도 훨씬 높은 성능을 보이고 있다. 또한 기존의 embedding generation time보다 3~4배 더 빠르며, 모델 학습 시간도 큰 폭으로 단축시킬 수 있다.
1. Introduction
서로 다른 두 binary function 을 비교하는 binary code similarity detection 기법은 표절 탐지, 멀웨어 탐지 등 다양한 분야에서 널리 쓰이고 있다.
IoT 펌웨어가 다양한 취약점을 보이는 등의 상황 속에서, 최대한 빨리 binary file의 similarity를 분석하여 시스템을 안전하게 지키는 것은 중요하다. 특히 ARM, MIPS 등 서로 다른 플랫폼에서 동작하는 binary file의 similarity를 분석하는 것이 중요한 이슈이다.
기존의 연구들은 cross-platform binary code similarity detection을 수행하기 위해 platform-independent feature만을 사용하여 graph matching을 하거나, control flow 로부터 high-level feature를 추출해 graphs를 embedding 하는 등의 연구를 진행했다.
그러나 이러한 연구들은
1) graph matching 알고리즘을 사용할 경우, 서로 다른 어플리케이션에 적용하기 어렵고
2) graph mathing 알고리즘을 통한 similarity detection은 graph matching 알고리즘의 efficiency에 종속되는데, graph matching 방식이 느려서 전체적으로 느려진다는 문제가 있다.
하지만 deep learning을 활용한 방식을 이용하면,
1) generating embeding 등의 binary analysis task가 줄어들고,
2) 유연하며,
3) 빠르다
라는 장점이 있다. 따라서 본 연구에서도 binary functions의 embeddings 를 생성하는데, deep learning을 활용할 것이다.
일반적으로, binary function은 control flow 그래프로 나타낼 수 있다. graph embedding network는 이런 control flow 그래프를 embedding으로 변환할 때 사용한다.
embedding을 학습시키는데에는 Siamese network를 사용하여 pre-trained model이 similarity detection에 사용될 embedding을 생산할 수 있도록 하였다.
또한 retraining 을 활용하여 pre-trained model이 추가적인 supervision을 획득하여 다양한 상황에서 적용될 수 있도록 하였다.
이러한 contribution을 적용한 'Gemini' 를 통해 기존의 모델보다 훨씬 빠르고 정확하게 similarity detection을 수행할 수 있다.
2. Binary code similarity detection
2.1. motivation problem: Cross-platform binary code search
만약 어떤 binary function이 주어지면, 우리가 관심있는 function과 유사한 기능이 해당 binary 에 존재하는지 식별하는 것이 주된 문제이다. 이처럼 기능의 유사성을 판단해주는 기능은 표절탐지, 펌웨어 이미지의 버그 검색 등 많은 보안 어플리케이션에 활용될 수 있다.
따라서 두 함수가 기능적으로 유사한지 판단하는 기능을 잘 구현하는 것이 중요하다. 이런 기능을 만들기 위해 고려해야 할 사항으로는 binary 파일 대상으로 해야하며, cross-platform에서도 동작해야 하고, 높은 정확도와 효율성을 지녀야 한다는 점이다.
2.2. Existing Techniques
기존에 binary code의 유사도를 판단하려는 많은 노력이 있었지만 주로 single platform에서만 동작해왔었다. cross-platform에서 동작하는 방식은 Pairwise Graph mathing과 Graph embedding 방식이 있었다.
- Pairwise Graph mathing
control flow 그래프의 input-output 쌍을 feature나 label로 하여 graph matching을 수행하였다.
그러나 이 방법은 굉장히 expensive 한 방법이다. 따라서 더 가벼운 방식으로 feature를 추출하는 등의 연구가 수행되었지만, 다양한 문제가 존재한다는 한계가 있다.
- Graph Embedding
확장성과 정확도를 동시에 충족하기 위해서는, 그래프를 벡터 등의 형태로 매핑해주는 Graph Embedding 방식이 좋다. similarity를 비교하기 위해서는 단지 두개의 그래프 벡터를 비교하면 되므로 굉장히 효율적이라는 장점이 있으며, feature vector는 LSH 방식을 통해 인덱싱되어지므로 search query가 O(1) 의 퍼포먼스를 보장받는다는 장점이 있다.
아래 그림은 Feng et al. 연구진이 최초로 Graph Embedding 방식을 활용하여 vulnerability search 문제에 적용한 연구의 workflow이다.
해당 연구에서는 binary function(firmware image나 known vulerability)를 입력받으면, raw feature를 추출해 ACFG 라는 control graph를 생성하였다. 이후 클러스터링 기반으로 학습시킨 codebook 활용 방식을 통해 ACFG를 feature vector 로 변환해주는 embdding network를 구성하였다. 이후 Firmware/vulnerability Database와의 비교를 통해 similarity를 계산하는 방식이다.

그러나 codebook을 활용한 방식의 경우
1) codebook을 생성하는 과정이 리소스를 너무 많이 소모하며
2) graph embedding을 하는데 필요한 런타임 오버헤드가 너무 크고
3) 검색 정확도는 codebook을 탐색할 때 사용하는 bipartite graph matching 의 정확도에 한정된다
라는 단점이 존재한다. (bipartite graph mathing은 항상 정확하지 않으므로)
2.3. Neural Network-based Embedding Generation
본 연구에서 제안하는 방식으로, ACFG를 embedding 하는 데, neural network를 활용하였다.
neural network 방식을 사용할 경우 다음과 같은 장점이 있다.
1) Better accuracy : 전체적인 그래프의 representation을 반영하고, 추가적인 supervision을 통한 retrained 과정을 거칠 수 있기 때문에 정확하다.
2) High embedding efficiency : graph embedding 과정에서 codebook에서 bipartite graph matching을 수행하지 않기 때문에 컴퓨팅 과정이 훨씬 효율적이다.
3) Fast offline training : training data size 에 linear 한 time complexity를 가지므로, traing 과정이 훨씬 빠르다.
3. Neural network-based model for embedding generation
3.1. Code Similarity Embedding Problem
다시한번 본 연구의 과정을 살펴보면, 특정 binary function f 의 기능을 flow graph ACFG g 로 나타내고, g 그래프를 embedding(=mapping Φ) 함수를 통해 벡터 μ로 나타내는 상황에서, embedding (mapping Φ) 과정을 보다 빠르고 효율적으로 처리하기 위해 ML 모델을 제안하는 연구이다.
3.2. Solution Overview
일반적으로 사용되는 graph embedding network는 classification 관점에 집중되어 있다. 하지만 우리의 모델은 classification 보다 비슷한지 아닌지를 구별하는 것이 더 중요하므로, differentiating the similarity에 집중하도록 설계하였다.
이를 위해 Siamese architecture를 구성하였는데, 이는 [그림 2]와 같이, Structure2vec 라는 embedding network를 통해 벡터값을 구한뒤, 두 벡터의 유사도를 cosine similarity 로 구하는 구조이다.
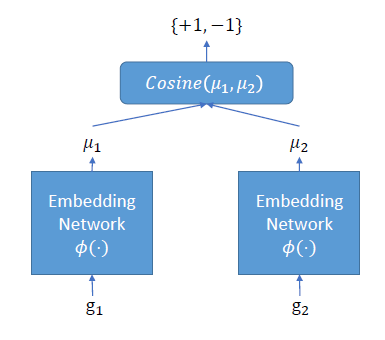
학습을 진행하려면 많은 양의 ground truth 데이터셋이 필요한데, 이를 모으기에는 한계가 존재한다. 이를 해결하기 위해 task-independent하게 pre-train한 뒤, 조금 더 나은 성능을 위해 task-specific 하게 Re-training하는 과정을 거칠 것이다.
4. Evaluation
4.1. Implementation and Setup
본 실험의 결과를 비교하기 위해 기존 연구에서 유사도를 측정하기 위해 수행하였던 Bipartite Graph Matching(BGM) 방식과 Codebook-based Graph Embedding(Genius) 방식을 baseline approach로 설정하여 함께 비교할 것이다.
데이터셋은 크게 4가지 종류로 구성하였는데,
Dataset 1 은 pre-train 모델의 neural network를 학습하고 정확도를 평가하는데 사용될 것이고,
Dataset 2 는 task-specific model을 평가하는데 사용될 것이고,
Dataset 3 은 efficiency evaluation을 위해 사용될 것이고,
Dataset 4 는 vulnerability dataset으로, case study를 위해 사용될 것이다.
아래 [그림 3]은 Dataset 1 의 세부정보를 나타낸 표이다.

4.2. Accuracy
본 절에서는 Gemini의 pre-trained 모델의 정확도를 측정해본다.
이를 위해 similarity testing data set을 만들어야 하는데, 다음과 같이 만들 수 있다.
우선 각각의 ACFG g 에 대하여, 𝝿<g, g1>= 1 과 𝝿<g, g2>=-1 을 만족하는 g1, g2를 선택한다. 1이 나오는 경우는 같은 소스코드에서 컴파일한 것이고, -1은 다른 소스코드에서 컴파일한 ACFG들이다.
이렇게 하면 총 26,265개의 pair를 생성할 수 있고, 추가적으로 ACFG를 split하여 large graph와 small graph로도 나누어보았다.
이렇게 학습을 진행해본 결과, [그림 4]와 같이 결과가 다른 baseline approaches에 비해 잘 나오는 것을 확인할 수 있다.

4.3. Hyperparameters
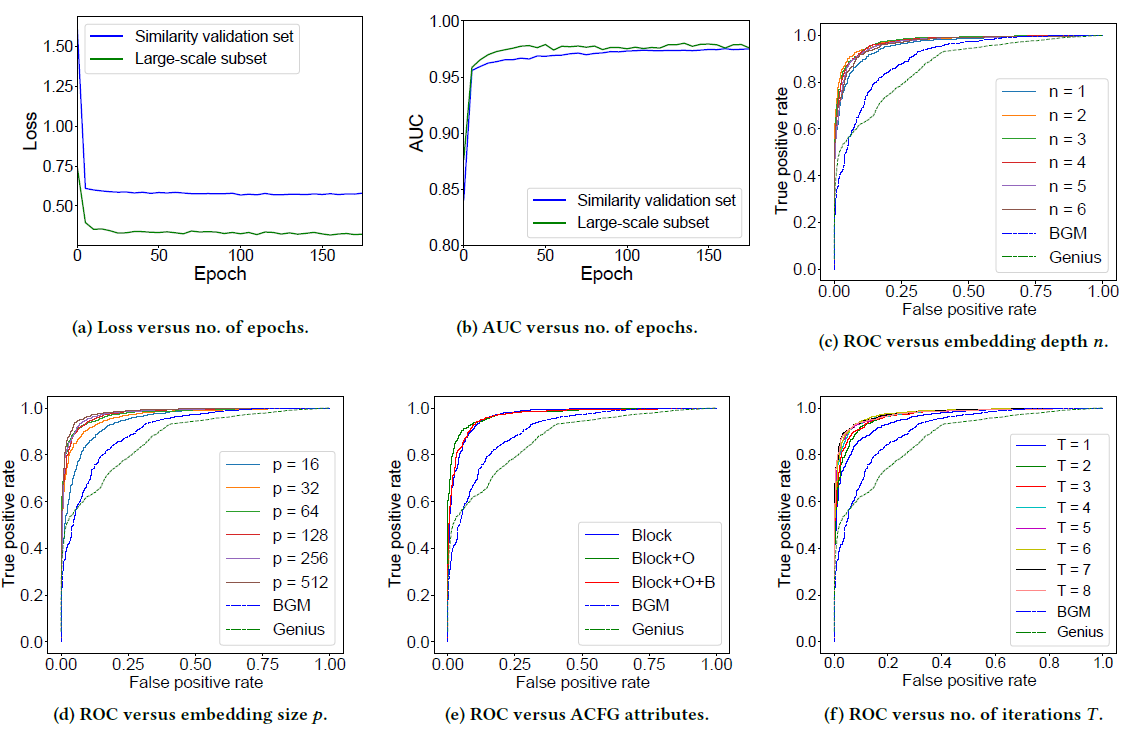
대표적인 hyperparameter로 number of epochs, embedding depth, embedding size, ACFG attributes, number of iteration 들을 선택하였다. hyper parameter 설정값에 따른 성능은 [그림 5]와 같다.

1) Number of epochs [Figure (a), (b)]
- 초기 5번의 epoch 동안 loss가 감소하며 그 이후로는 거의 비슷함
- 모델이 빨리 학습됨을 알 수 있다
2) Embedding depth [Figure (c)]
- depth가 2일 경우 가장 AUC value가 크다
- 하지만, depth를 늘린다고 성능이 엄청 좋아지지는 않는다.
3) Embedding size [Figure (d)]
- size가 너무 커지면 오래걸리므로 512가 딱 적절하다.
4) ACFG attributes [Figure (e)]
- 3가지 경우 중, 8가지 attributes 선택한 경우 (Block + O + B) 가 가장 성능 좋았다.
5) Number of iterations [Figure (f)]
- iteration이 5 이상일 경우 성능이 좋았다.
- 모든 그래프가 10 이상의 크기를 가지므로, 5-hops 이상의 hop이 있어야만 local information을 그래프 전체에 전달할 수 있다.
4.4. Efficiency
Dataset 3을 통해 Gemini와 baseline approach의 efficiency를 비교했다.
efficiency 비교 위해서
1) 각 함수에서의 ACFG extraction time
2) 각 ACFG의 embedding generation time
3) 전체적인 과정에서 걸리는 시간
3가지를 비교해보았다. 그 결과는 [그림 6] 과 같다.
Gemini의 경우, 간단한 graph matching algorithm을 사용하고, codebook을 사용하지 않고, matrix 연산이 가능하다는 등의 장점이 있어 baseline approach 보다 efficient 한 것을 확인할 수 있다.
4.5. Training time
새로운 펌웨어가 나오면 모델을 업데이트해야하기 때문에 training time 도 baseline approach와 비교해봤다.
baseline approach 중 하나인 Genius는 codebook을 사용하고, spectral clustering 이라는 unsupervised learning을 수행하는데, 해당 방식은 time complexity가 굉장히 높다 (O(n^2)).
반면 본 연구에서 제안한 Gemini 모델은 필요한 epoch 수도 적고, time complexity가 낮기 때문에(O(n)) training time 이 굉장히 줄어든다.
4.6. Understanding the Embeddings
몇개의 binary function 을 다양한 방식으로 컴파일하여 생성한 embeddings를 t-SNE 기법을 통해 2D로 시각화한 결과 [그림 7]과 같은 결과가 나왔다.
이는 같은 binary function을 다양한 방식으로 컴파일 하더라도 비슷한 특성을 가지게 된다는 것을 의미한다.

4.7. Accuracy of Task-specific Retrained Model using Real-world Dataset
Dataset 1을 통해 학습된 task-independent 한 pre-trained 모델을 retrain 하려 한다.
Dataset2 에서 ACFG들을 몇개 뽑고, Dataset4에서 두개의 vulnerabilities를 선정하였다. 각각의 vulnerabilites들을 specific-task라고 가정하고, Dataset1에서 각각의 vulnerability를 가지는 function을 찾도록 하였다. 이를 수행하기 위해서 앞서 만든 pre-train 모델을 retrain 하였다.
그 결과 Gemini는 top-50 function에 대하여 각각 80% 이상의 accuracy를 보였다. 이는 기존 연구의 accuracy가 20% ~ 50% 였던 점을 감안하면 엄청난 성장이다.
전체적으로 본 연구팀의 접근 방식을 통해 상위 50개 결과 중 Genius보다 평균적으로 25개 이상의 새로운 취약한 펌웨어 이미지를 식별할 수 있었다.
6. Conclusion
본 논문에서는 binary function의 embedding을 생성하기위한 deep neural network-based 접근방식을 채택하였다.
실제 Gemini라 불리는 시스템을 구현하였으며, 최신의 approach에 비해서도 accuracy, embedding generation time, training time 등 다양한 지표에서 좋은 성능을 보이는 것을 확인하였다.
뿐만 아니라 retraining을 통해 vulnerable한 펌웨어를 보다 정확하게 탐지할 수 있음을 보였다.
Reference
Xiaojun Xu, Chang Liu, Qian Feng, Heng Yin, Le Song, and Dawn Song. 2017. Neural Network-based Graph Embedding for Cross-Platform Binary Code Similarity Detection. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security (CCS '17). Association for Computing Machinery, New York, NY, USA, 363–376.
'논문' 카테고리의 다른 글
| [논문] Detecting Malicious Social Robots with Generative Adversarial Networks (0) | 2022.03.02 |
|---|---|
| [논문] Generative Adversarial Nets (0) | 2022.02.08 |
| [논문] Detecting Credential Spearphishing Attacks in Enterprise Settings (0) | 2021.12.14 |
| [논문] RiskTeller: Predicting the Risk of Cyber Incidents (0) | 2021.11.30 |
| [논문] Hardware Performance Counters Can Detect Malware: Myth or Fact? (0) | 2021.11.24 |



