
shine's dev log
Association Rules(Support, Confidence, Lift, A-priori 알고리즘) 본문
1. Association Rules
Association Rules 란, items 사이의 관계를 나타내는 법칙을 찾는 방법이다.
Association Ruels 에서 항상 나오는 예제가 바로 시장에서 물건을 사는 예제이다.
시장에 과일, 야채, 고기, 생선이 있다고 할 때 "고기와 생선를 산 사람이 야채도 살 확률은 얼마인가?" 등과 같이 여러 상품간의 관계를 나타낼 수 있는 질문에 답을 해줄수 있는 것이 Association rules 이다.
Association Rules 는 X -> Y 로 표현이 가능하며, 이는 "X를 선택할 때, Y를 선택할 확률"로 표현할 수 있다.
대표적으로 Association rues 가 활용될 수 있는 영역은 앞서 살펴본 시장 외에도 병원, UX 디자인, 넷플릭스 등 다양한 영역이 있다.
2. Support, Confidence, Interest, Lift
Association Rules 에 활용되는 지표로는 다양하게 존재한다. 예시를 통해 각 지표들에 대해 자세히 알아보자.
예시는 아래와 같이, Item은 5가지가 있고, 8개의 basket에는 각각 여러개의 item들이 담겨있는 상황이다.
Items = {milk, coke, pepsi, beer, juice}
B1 = {m, c, b}
B2 = {m, p, j}
B3 = {m, b}
B4 = {c, j}
B5 = {m, p, b}
B6 = {m, c, b, j}
B7 = {c, b, j}
B8 = {c, b}
- Frequent itemsets
자주 등장하는 itemsets를 확인할 수 있는 지표이다. Frequent itemsets에는 Support threshold(Minimum support) 라는 일종의 '한계값' 이 필요하다. item의 빈도가 threshold 값을 넘기면 Frequent 하다고 할 수 있는 것이다.
위의 예시에서, Support threshold가 3 basket 이라고 할 때 Frequent itemsets를 찾으라고 하면, 3번 이상 선택된 itemset으로는 {m}, {c}, {b}, {j}, {m, b}, {b, c}, {c, j} 7가지를 찾으면 된다.
- Support (X -> Y)
전체 경우에서 집합 X와 Y를 모두 구매하는 경우의 수를 의미하는 지표이다.
수식으로는 n(X∪Y) / n(ALL) 이다. (상황에 따라서는 그냥 n(X∪Y) 만을 의미하기도 한다.)
위의 예시를 살펴보자. {m, b} -> c 라는 Association rule 에서, Support는 집합 {m, b} 와 {c} 를 모두 포함하는 경우, 즉 B1 ~ B8 에서 {m, b, c}를 모두 구매하는 경우의 수를 의미한다.
따라서 {m, b} -> c 의 Support는 2/8 이다. (상황에 따라서 그냥 2라고 표현할 수도 있다.)
- Confidence (X -> Y)
집합 X를 구매하는 경우에서 Y 도 구매하는 경우의 비율, 즉 조건부 확률을 의미한다.
(X와 Y를 모두 포함하는 경우의 수) / (X를 포함하는 경우의수) 이므로, 수식으로는 n(X∪Y) / n(X) 이다.
일반적으로 Confidence가 높을수록 해당 Association rule이 유용할 가능성이 높다고 판단한다.
위의 예시를 살펴보자. {m, b} -> c 라는 Association rule 에서, Confidence는 (집합 {m, b, c} 를 모두 포함하는 경우의 수) / (집합 {m, b} 를 포함하는 경우의 수) 를 의미한다.
따라서 {m, b} -> c 의 Confidence 는 2/4 = 0.5 이다.
- Interest (X -> Y)
Y를 구매하는 경우의 수와 X->Y를 구매하는 경우의 수를 비교하여, X->Y가 얼마나 흥미로운지 나타내주는 지표이다.
직관적인 의미는, '모든 사람들에게 Y를 추천했을때에 비해, X를 구매한 사람에게만 Y를 추천했을때, Y를 구매할 확률이 증가되는 정도' 이다.
(X -> Y 의 Confidence) - (Y의 발생 확률) 이므로, 수식은 | conf(X -> Y) - support(Y) | 이다.
위의 예시를 살펴보자. {m, b} -> c 라는 Association rule 에서, conf(X-> Y)는 2/4 였고, Y가 발생할 확률 P(Y) = 5/8 이다. 따라서 Interst(X -> Y) = | 2/4 - 5/8 | = 1/8 이다.
- Lift (X-> Y)
Interst와 동일한 의미를 가지며, 역시 직접적으로 X와 Y의 관계를 나타내주는 지표이다. Lift값이 1보다 크면 X와 Y의 relationship이 강하다는 것을 의미한다.
수식으로는 conf(X -> Y) / support(Y) 으로 나타낼 수 있다. (Interest와 같은 의미인 것을 알 수 있다.)
위의 예시를 살펴보자. {m, b} -> c 라는 Association rule 에서, conf(X-> Y)는 2/4 였고, support(Y) = 1/4 이다. 따라서 Lift(X, Y) = (1/2) / (1/4) = 2 이다.
3. A-priori 알고리즘
Association Rules 분석 알고리즘에는 A-priori algorithm, FP-growth algorithm, PCY algorithm 등 다양한 알고리즘이 존재하는데, 가장 쉽고 자주 사용되는 A-priori 알고리즘에 대해 살펴보자.
앞서 살펴본 Confidence, Interest, Lift 등의 지표는 X -> Y 관계에서 X와 Y 사이의 관계를 나타내주는 지표이다.
그런데 위의 예시에서, 모든 X -> Y 관계를 생각해보면 {m} -> {c}, {m} -> {c, p}, {m} -> {c, p, b}, {m, c} -> {p}, .. 등등 엄청나게 많은 경우가 쏟아진다.
X와 Y가 될수 있는 경우의 수를 따져보면 엄청 많고, 각각에 해당하는 Confidence, Interest, Lift 등의 지표를 일일히 다 구한다면 시간이 엄청 많이 걸릴 것이다. 위의 예시에서는 전체 item이 5개였지만, 실제 상황에서는 item이 수십, 수백개일 것이고 X -> Y의 경우의 수는 기하급수적으로 증가할 것이다.
이런 문제를 해결하고자 나온 것이 바로 A-priori 알고리즘이다. 전체 item 중에서 어느 정도 연관이 있을법한 item들을 추려주어 보다 계산시간을 줄여줄 수 있다.
예시를 통해 살펴보며 A-priori 알고리즘이 어떻게 연관이 있을법한 item들을 추리는지 알아보자. 예시에 사용되는 정보는 아래와 같다.
Items = {milk, coke, pepsi, beer}
B1 = {m, c, p, b}
B2 = {m, c, b}
B3 = {m, c}
B4 = {c, p, b}
B5 = {c, p}
B6 = {p, b}
B7 = {c, b}
Support threshold = 3
Step1) itemset 데이터를 통해 1-frequent itemset 을 찾는다.
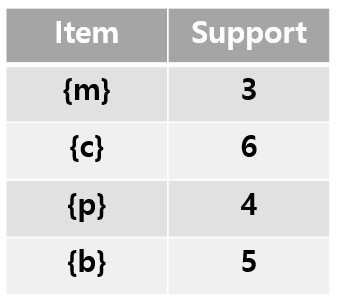
1-frequent itemset을 통해 크기가 1인 itemset의 support를 모두 구한다. 모두 support threshold=3 보다 높으므로 모두 1-frequent itemset에 포함된다.
Setp 2) 1-frequent itemset를 가지고 Self-Join과 Prune 과정을 거친다.
Self-Join 과정은 1-frequent itemset의 item ( {m}, {c}, {p}, {b} ) 들을 가지고 크기가 2인 모든 itemset을 만드는 과정이다.
그 결과 {m, c}, {m, p}, {m, b}, {c, p}, {c, b}, {p, b}가 생성된다.
Prune 과정은 Self-Join으로 생성된 itemset 의 item 중, 1-frequent itemset에 포함되지 않은 녀석들을 잘라주는 과정이다. Self-Join의 결과물 {m, c}, {m, p}, {m, b}, {c, p}, {c, b}, {p, b} 의 각각의 item들은 모두 1-frequent itemset에 포함되므로 해당 과정에서는 Prune 할 후보가 없다.
Step 3) Self-Join, Prune 한 결과를 바탕으로 2-frequent itemset 을 찾는다.
우선 Step 2 에서 Self-Join, Prune 한 결과를 바탕으로 Item count를 해보면 아래 표와 같다.

이 중에서 support threshold=3을 넘지 못한 {m, p}와 {m, b}를 제거해주면 아래와 같은 결과가 나오게 되고, 이것이 2-frequent itemset이다.
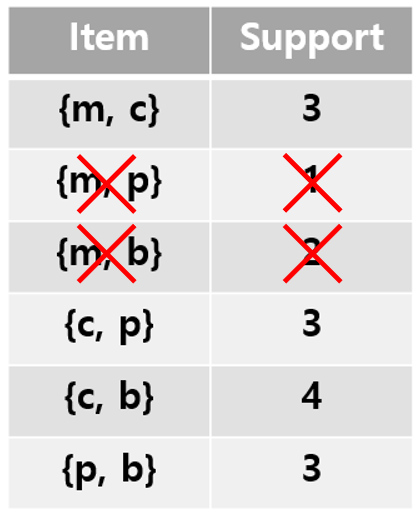
Step 4) 2-frequent itemset를 가지고 Self-Join, Prune 과정 수행
Self-Join 과정을 위해 {m, c}, {c, p}, {c, b}, {p, b}를 가지고 크기가 3인 itemset를 만들어보면 {m, c, p}, {m, c, b}, {m ,p, b}, {c, p, b}가 나온다.
Prune 과정을 위해 {m, c, p} 의 subset을 계산해보면, {m, c}, {m, p}, {c, p} 인데, 이 중 {m, p}가 2-frequent itemset에 포함되어있지 않으므로 제거된다.
이런식으로 Prune 을 모두 진행하면 {c, p, b}만 남는다.
Step 5) Self-Join, Prune 한 결과를 바탕으로 3-frequent itemset 을 찾는다.

3-frequent itemset candidate의 유일한 {c, p, b}가 support threshold=3을 넘지 못하므로 모든 과정을 종료한다.
즉, A-priori 알고리즘은 itemset을 이용해
k-frequent itemset을 구한 뒤, Self-join / Prune 과정을 통해
(k+1)-frequent itemset candidate를 구하고, support threshold 를 통해
(k+1)-frequent itemset를 구하는 과정으로 진행된다.
A-priori 알고리즘은, 만약 frequent 하지 않을 것으로 예상되는 itemset이 존재하면, 해당 itemset을 포함하는 모든 집합들도 infrequent 하다고 예상하여 그냥 계산하기를 멈춰버리는 것이다.
이렇게 함으로써, 모든 item에 대한 경우의 수를 고려하지 않고,
오직 frequent itemset에 포함된 놈들에게만 association rules (confidence, lift, interest) 를 고려하면 되기 때문에 계산량이 훨씬 줄어들 수 있다.
오늘 배운 내용을 정리해보면,
1. Association rule은 item 사이의 관계를 나타내는 규칙이다
2. Association rule을 평가해주는 지표로는 support, confidence, interest, lift 등이 있으며, interest와 lift가 가장 직접적인 연관 관계를 설명해준다.
3. 해당 지표들을 계산하는데 걸리는 시간을 줄이기 위해 A-priori 등의 알고리즘을 사용할 수 있다.
위 내용은 공부하며 정리한 것으로, 오류가 있을 수 있습니다.
'머신러닝' 카테고리의 다른 글
| [Pytorch] GAN 구현 및 학습 (2) | 2022.03.12 |
|---|---|
| [ML] Deepfake Detection 성능 분석 (8) | 2022.02.26 |
| KL divergence와 JSD의 개념 (feat. cross entropy) (1) | 2022.02.19 |
| [Recommender system] 영화 추천 시스템 (0) | 2022.01.23 |
| PCA (Principal Component Analysis) : 주성분 분석 이란? (36) | 2021.12.21 |



