[논문] RiskTeller: Predicting the Risk of Cyber Incidents
논문 제목 : RiskTeller: Predicting the Risk of Cyber Incidents
0. Abstract
모든 시스템에는 취약점이 존재한다.
이러한 취약점으로부터 피해를 최소화하기 위해서는, risk level을 정량화하고 예측하는 시스템 필요하다.
저자는 RiskTeller 라는 시스템 고안하였다. 해당 시스템은 binary file appearance log를 통해 위험을 예측하는 구조이다.
우선 사용자 각각의 usage pattern 을 담은 profile 을 분석한 후, 각 profile 별로 얼마나 위험에 처해져있는지 fully/semi-supervised learning 방법 통해 예측한다.
1년동안 각 machine에 사용된 모든 binary 데이터 (machine profile) 를 통해 RiskTeller를 평가하였으며, 실험 결과 RiskTeller는 높은 precision으로 위협을 예측할 수 있었다.
1. Introduction
지난 20년간 cyber-threat ecosystem이 점차 다양하고 진보된 공격을 당하고 있고, 따라서 이런 위협을 예측하는 것이 중요해지고 있는 상황이다.
이러한 위협을 예측하는 연구들은 그렇게 많지 않은 상황이며, 그 연구들도 demographics, network connectivity behavior, web browsing behavior 등 한정된 dataset을 사용하였다.
하지만 본 연구에서는 뚜렷한 보안 상태 정보를 제공하고, 보다 나은 정확도를 줄 수 있는 dataset을 활용한다.
RiskTeller는 각각의 machine별로 binary appearance log를 분석해서, 어느 machine이 malware에 risky한 지 예측하는 시스템이다.
dataset은 18개사, 600,000개의 machine에서 수집되었으며, 실험기간동안 44억개의 binary file appearance event가 발생했다.
이 dataset을 통해 각 machine별로 89개의 feature profile을 만들었다.
feature는 volume of events, temporal patterns, application category, rarity of file, past threat history 등의 카테고리를 기준으로 만들어봤다.
또한 일반적으로, ML 학습 과정에서 ground-truth 정보가 많을수록 모델의 정확도가 높아지지만, 실제로는 ground-truth 정보가 부족한 경우가 많다.
하지만 비슷한 machine의 profile을 통해 unlabel된 user의 fuzzy label에 label을 부여함으로써 semi-supervised learning 가능하도록 하였다.
RiskTeler는 supervised/semi-supervised learning통해 높은 accuracy를 보장받을 수 있다.
2. Why Cyber risk prediction?
사이버 범죄가 늘어남에 따라 각 개인과 기업들은 사이버 범죄를 미리 예측하고 피해를 최소화하는데 노력해야 한다.
cyber insurance 회사에서, 사이버 공격 risk 를 판단하는 방법은 굉장히 부정확하다. 따라서 더 높은 정확도와 예방 방법 필요로한다.
Detection 영역에서는 false positive (malware 아닌데 맞다고 하는것) 은 정상적인 행위를 못하게 하므로 회사에 큰 손실이다. 따라서 TP를 높이면서 FP를 낮게 유지시키는게 관건이다.
하지만 Prediction 영역에서는 최대한 모든 공격 가능성 알고 싶어 한다. prediction 관점에서 FP를 낮게 유지하는게 엄청 힘들지만, detection 영역에 비하면 큰 손실은 아니다.
기존의 연구들에서는 95%이상 정확도로 예측하기 위해서는 20% 이상의 FP rate를 만들어내야만 했다.
하지만 우리 연구에서는 이 FP rate를 더 줄일 방법을 모색한다.
3. Dataset
본 연구에서는 앞서 말했듯이 새로운 binary file appearance log를 기록한 데이터 (appearance는 다운로드, 컴파일 결과 등으로 발생) 사용할 것이다.
binary file log에서 주목한 부분으로는 enterprise & machine identifier, SHA2 file hash, file name & directory, file version, timestamp for the first appearance on the machine, file signer subject in the certificate 등이 있다.
3.1. Data Preprocessing
획득한 데이터를 최적화시키기 위해 normalization과 cleaning을 진행.
파일과 디렉토리 이름 정규화, 버전 정보 정규표현식으로 표현, 복사된 파일의 숫자 (hello(2).txt 이런거) 제거하였다.
또한 binary file을 잘 구분할 수 있도록 윈도우의 CSIDL 참고하여 3 depth 로 디렉토리 구성하였다.
- 예를들어 크롬은 /CSIDL_PROGRAM_FILES/google/chrome 에 위치시킴
3.2. Ground truth
ML 모델을 학습시키기 위해서는 dataset에 대한 feature extraction과 labeling이 선행되어야 한다. 본 연구에서는 전체 datasets을 크게 두가지 period 로 구분하였다. 우선 feature extraction period 가 먼저 나타나고, 이어서 labeling period 가 나온다.
feature extraction period 기간동안은 각 feature의 값을 계산한다. 해당 기간동안 계산된 feature 값과, labeling period 기간에 나온 ground truth 결과를 연결짓는다.
labeling은 기본적으로 'clean machine'과 'infected machine' 으로 구분하였다.
'unknown file'이 엄청 적고, malware로 알려진 파일이 하나도 없고, 감염된 적이 한번도 없으면, 해당 machine profile을 'clean machine'으로 설정하고, malware 로 알려진 파일이 있으면 해당 machine profile을 'infected machine' 으로 설정한다.
추가적으로, ground truth build하는데 3가지 데이터셋 사용되었다.
1) Anti-Virus company에서 획득한 benign/malware hashes dataset (labeled 됨, 앞에서 normalization 한 데이터셋)
2) AV product에 의해 malware라고 판단되었지만, 사용자에 의해 benignware라고 입증된적 없는 file hash datasets (대부분 malware일 것)
3) Machine의 Network activity로 탐지된 malware dataset (회사의 IPS 제품에 의해 탐지)
4. Building the machine profiles
4.1. feature discovery
학습에 사용될 feature를 아래 표와 같이 카테고리 별로 구분하였다.
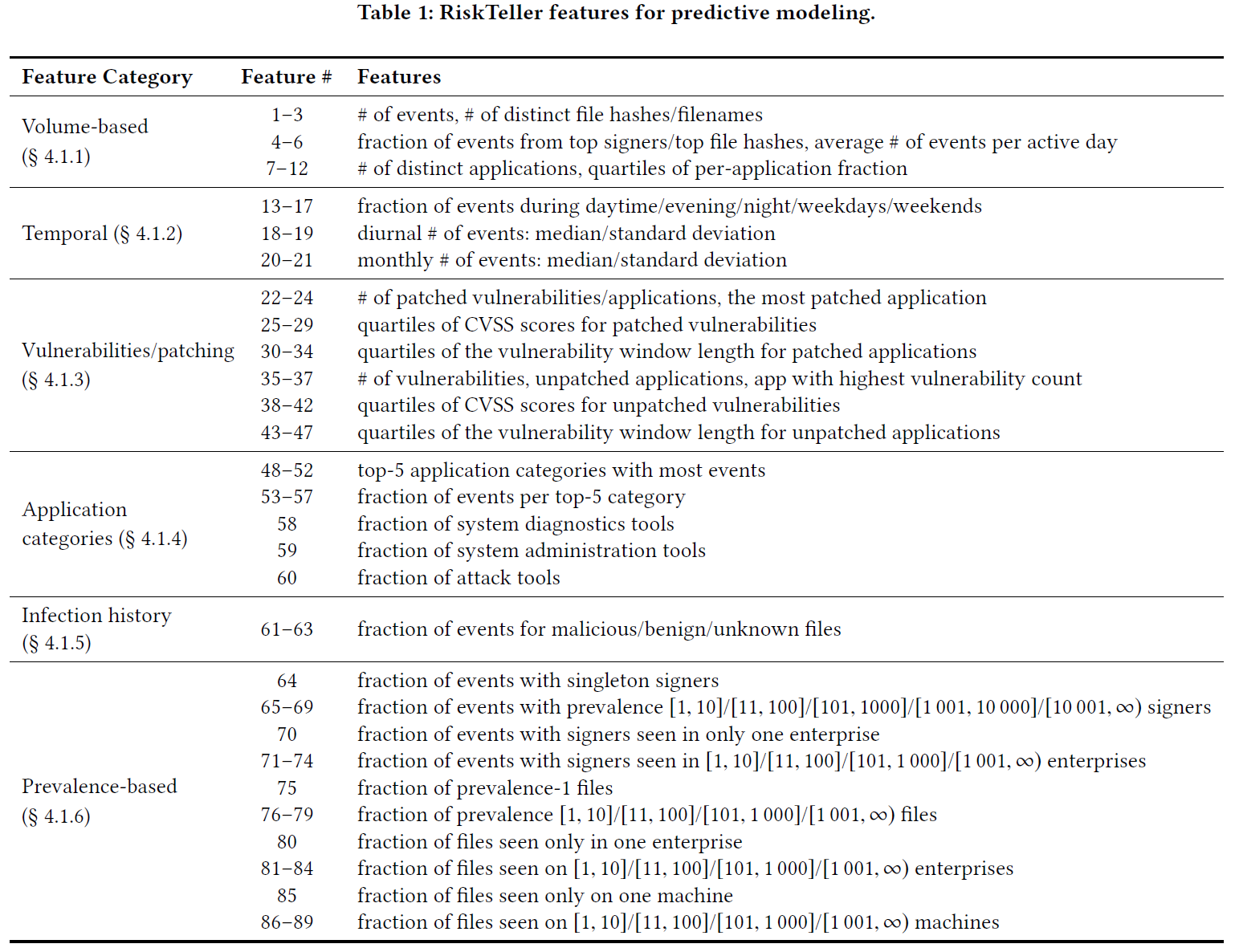
1) Volume-based category : events의 개수, 개별 파일의 개수, 자주 사용되는 파일 리스트의 사용 비율, 어플리케이션 별 events 생성 확률
2) Temporal behavior : 사용시간에 따른 분류 (저녁시간에 사용할수록 개인적 용도 -> risky하다), 낮/밤/주중/주말 사용 비율, 각 일/월 별 event 생성 개수 median, deviation
3) Vulnerabilities and Patching behavior : 취약점 발견되고, 이를 패치하기까지 시간(vulnerability windows), 패치한 횟개수(5개 vendor의 어플리케이션 기준), 패치 안된 어플리케이션 개수/CVSS score (NVD, CVSS 참조) 등
4) Application Category-Based Features : 많은 events를 생성하는 어플리케이션 category top-5, top-5 category마다 events 발생 비율, system diagnostics tools 비율, system administration tools 비율, attack tools 비율
5) Infection history : malicous/benign/unknown 파일의 events 발생 기록
6) Prevalence-Based Features : malware는 benginware에 비해 prevalence(널리 퍼짐) 하지 않는 경향이 있으므로 관련 정보 사용(singleton signers, singers seen in only one enterprise, prevalence-1 파일 등)
4.2. A Look at the Dataset
가장 relevant feature 9가지를 ECDF 로 나타내면 아래 그림과 같다.
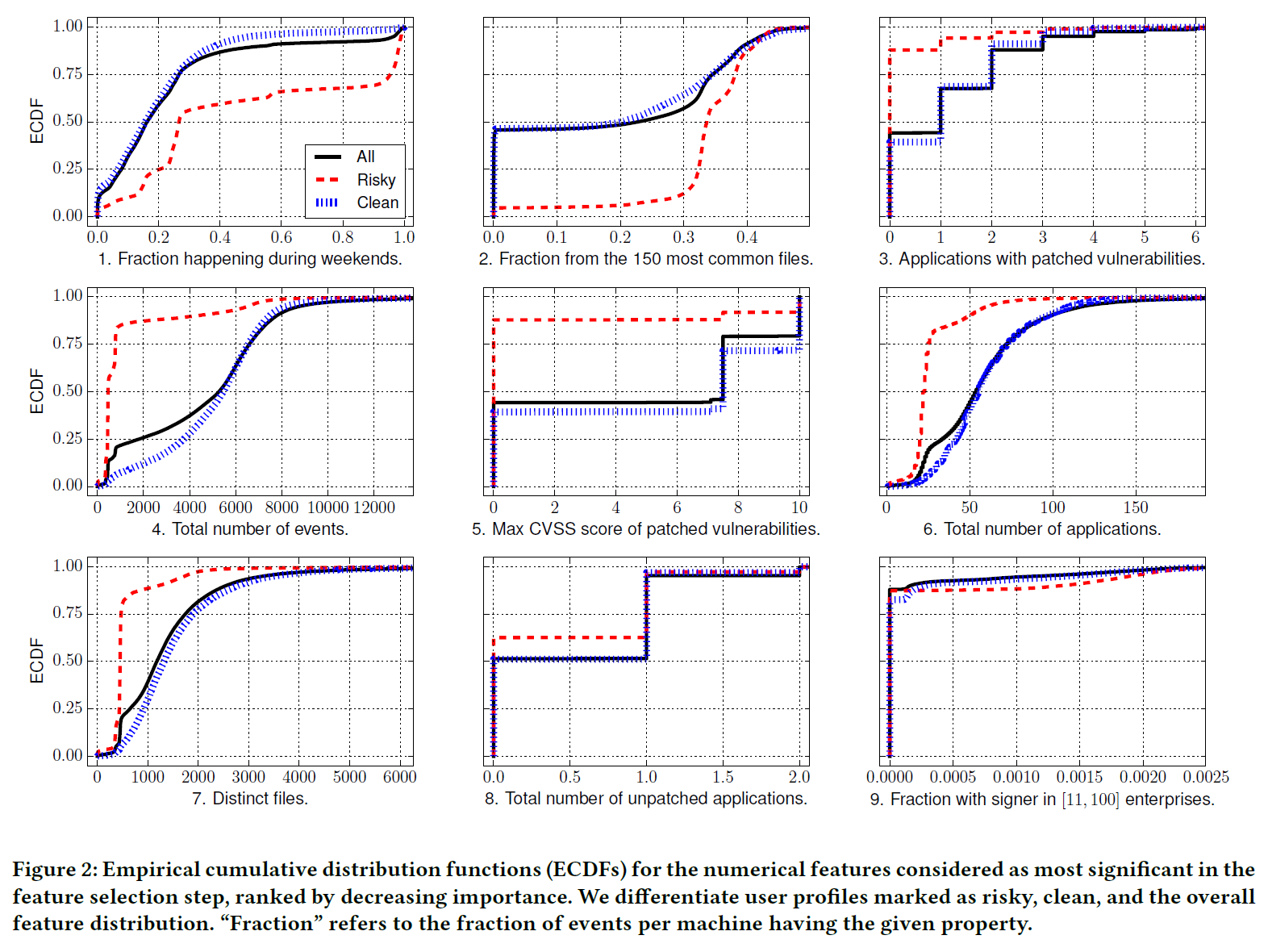
그래프를 해석 해보자면, 예를 들어 4번 그래프를 통해 risky한 사용자는 일반적인 사용자에 비해 binary 설치 횟수가 매우 적다는 것을 알 수 있다.
2번 그래프를 통해 risky한 사용자의 대부분의 프로그램은 흔한 프로그램이라는 것을 추론할 수 있으며, 1번 그래프를 통해 risky한 사용자는 주말에 사용률이 더 높다는 것을 추론할 수 있다.
5. Predicting analytics
앞서 정의한 features들은 ML에 들어갈 input 들이다. Random forest와 semi-supervised learning, 두가지 알고리즘 적용해볼 것이다.
참고로, 앞서 정의한 features 중 numeric한 데이터가 아닌 경우, one-hot encoding을 사용하여 numeric하게 encoding 시켜줬다.
5.1. Random Forest Classifier
RFC는 여러개의 decision trees 로 이루어진 앙상블 모델이다. bias-varaiance trade-off 를 통해 variance를 최대한 줄이는 방식으로 동작한다.
본 모델에서는 800개의 trees 사용하였는데, tree 개수 더 늘려도 accuracy 향상 없기 때문이다. (Liaw and Wiener et al. [18])
RFC 모델을 사용한 이유는 다음과 같다.
1) categorical, numerical feature 사용 가능하며, feature normalization 필요가 없다.
2) 이전에 본 적 없는 새로운 데이터로도 잘 동작한다.
3) Tree 구조가 직관적으로 prediction 과정을 이해하는데 도움을 준다.
4) The output of RFCs is an well-calibrated probability that the model assigns to belonging to a given class. (뭔말인지 모르겠음)
5) scalable 하며, large-scale dataset에도 잘 동작함
5.2. semi-Supervised Learning
직접 labeling을 하지 않으면서도 준수한 accuracy를 유지할 수 있는 방법이다. 특히 ground truth 데이터가 unbalance하거나 작을 때 유용하다.
본 모델에서는 새로운 SSL 기반의 inductive learning engine 제안하였는데 기본 원리는 다음과 같다.
각 machine profile마다 사용자의 행동을 담은 n-dimensional feature vector를 입력값으로 준다. profile (X(i)) 이 risky하면 0으로 라벨링, safe하면 1로 라벨링할 것이다.
risk prediction model F는 risk score라는 F(X(i)) 값을 통해 i 번째 machine의 infection risk를 측정한다.
risk score는 1) [0, 1] 범위이며, 연속적이다 2) 비슷한 user profile을 가지면 risk score도 비슷하다는 특징을 가진다. risk score를 통해 확실히 infected된지, clean한지 애매한 machine의 infection 확률을 계산할 수 있다.
user profile 비슷하면 벡터 X(i) 도 비슷하므로, A-priori 알고리즘 통해 user profile 간의 similarity 계산하여 optimizing 하였다.
만약 user profile X(i)가 라벨링되어있지 않았다면, similar한 X(j)의 weighted average를 이용해 라벨링하였다. (weighted 정도는 similar 정도에 비례)
6. Experiments and results
6.1. RiskTeller parameters
RiskTeller 모델은 크게 두가지 parameters set을 가진다.
1) feature extraction, labeling period length
- feature extrantion period(M month)와 labeling period(N month)로 구분 가능하다.
- dataset이 1year data이므로 M + N <= 12 되도록 설정하였다. 아래 그림과 같이 M과 N에 따른 AUC score를 살펴보면, M>=5 and 6<=N<=8 일 경우 성능이 좋은 것을 파악할 수 있었다.

2) Thresholds for the Ground Truth
- Ground truth는 AV company의 제품 성능, 중복 여부 등에 따라 결정되므로 오차가 있다.
- 따라서 Threshold 값 정해서 이 오차를 줄여줬다.
6.2. Prediction Results
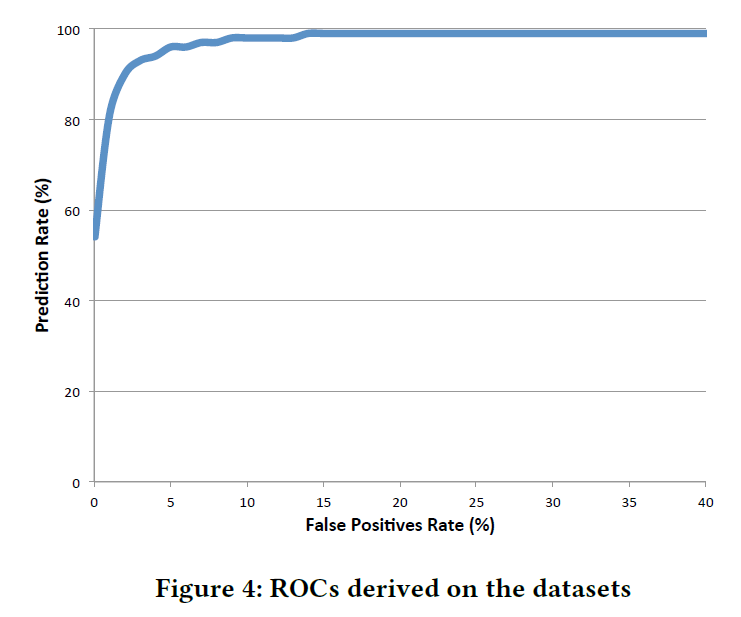
위 그림은 제안된 모델을 10-fold cross validation 거친 후 나온 결과이다. RiskTeller 는 단 5%의 FP rate으로 95%의 accuracy를 가질 수 있다. 기존 연구의 95% accuracy에 20% FP에 비하면 큰 성능 향상을 이뤄냈다.
6.3. Feature Significance
가장 영향력이 큰 feature를 선택하기 위해 mean decrease impurity methodology (Mean Decrease Gini) 사용하였다.
해당 방법은 각 feature가 model에 적용되는 것이 전체 classification의 impurity(불순도) 를 얼마나 감소시키는지 측정함으로써 동작한다.
그 결과 아래 표와 같은 결과 나왔다. 일반적인 상식과 다르게, infection history fearures는 영향력이 크지 않은 feature였다.

7. Discussion
dataset 들의 feature가 공격자들이 공격하기 전 (feature extraction period)에 benign한 목적으로 수집되었기 때문에, 제안 모델을 회피(evasion)하는 문제는 발생하지 않았다.
또한, 일반적으로 공격자들의 특성을 파악하는 malware detection 모델과는 다르게, RiskTeller는 victims들의 데이터를 대상으로 만든 모델이기 때문에, 다양한 방식으로 공격이 들어와도 정확하게 판단할 수 있다. (victims 들의 행동은 거의 변하지 않기 때문에)
본 모델은 다른 모델에 비해 굉장히 높은 성능을 가지고 있으며, 실제 산업계에서도 risky한 machine/user 을 찾아내 공격에 대비하는데 사용될 수 있을 것으로 기대하고 있다.
8. Related work
1998년 Korzyk 는 단순한 time series analysis로 공격 예측 연구 수행하였다.
2013년 Jones et al.은 Game theory로 공격 예측, 2015년 IARPA CAUSE 프로젝트에서는 large amount of Internet data와 ML 모델 통해 공격 예측 연구 수행했다.
또한 user 의 행동을 통해 공격 예측을 수행한 다양한 연구 있었다. 그러나 accuracy가 낮거나, 높아도 FP가 너무 높았다는 문제가 있었다.
SSL(Semi-Supervised Learning)을 통한 공격 예측 연구도 2016년 Han and Shen 에 의해 수행되었지만, ground truth가 manualy 지정되어야 했으므로 overhead가 너무 컸다는 문제가 있었다.
반면 본 연구에서는 SSL을 ground truth의 완성도를 검증하고 enrich 하는데 사용하였다.
9. Conclusion
본 연구에서는 낮은 FP rate를 통해 높은 accuracy 가지는 모델 제안하였다.
특정 취약점 타입에 맞춤화 하거나, 개인 사용자들을 대상으로 수행하는 모델을 개발하는 등 연구를 확장해나갈 예정이다.
10. 고찰
본 연구에서는 사용자의 행동 분석을 통해 앞으로 해당 machine에 infection이 발생할지를 예측하는 연구를 수행하였다.
특히 전체 period를 feature extraction period와 labeling period로 구분하여 전자 구간에서는 오직 feature 값만 계산하고, 후자 구간에서 infected 인지 safe 인지 판단하는 과정이 인상깊었다.
또한 본 연구에 사용된 data의 경우 ground truth가 명확하지 않은 data가 많았는데, 이를 risk score를 통해 추론하고, ground truth를 결정한 뒤, SSL 모델을 통해 학습시킨 과정 또한 흥미로웠다.
이번 논문에서도 역시 risk score 를 계산하는 과정에 나온 수식들이 이해가 다 되지 않았는데, 데이터 마이닝과 선형대수 파트를 더 공부해보고 다시 공부해야되겠다.
Reference
Leyla Bilge, Yufei Han, and Matteo Dell'Amico. 2017. RiskTeller: Predicting the Risk of Cyber Incidents. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security (CCS '17). Association for Computing Machinery, New York, NY, USA, 1299–1311.